
According to Gartner’s supply chain security risk report in 2021[1], breaches of confidential or sensitive information constitute another major factor contributing to software supply chain risks. Hackers steal hard-coded credentials in source code, building logs, and infrastructure, such as API keys, encryption keys, tokens, and passwords, or locate vulnerabilities in a leaked software bill of materials (SBOM) and source code to attack the target system, which significantly increases security risks. Therefore, the aforementioned sensitive data must be protected throughout application and management. Security technologies including Secure Multi-Party Computation (MPC), Zero-Knowledge Proof (ZKP), and Trusted Execution Environment (TEE) can be employed for different applications.
Data-driven collaboration between upstream and downstream enterprises is indispensable during the whole life cycle of a software supply chain. For example, data support (list of software compositions and source code) from the software developer is required at the SBOM generation and maintenance stage while the latest vulnerability data provided by third-party security organizations are necessary for detecting vulnerabilities in the software supply chain. Considering such data is sensitive as it is the core assets of upstream and downstream enterprises and is related to end users’ software security, once it is leaked, the risk of end users being hacked will immensely increase. This renders it intractable to directly exchange this sensitive data between these enterprises. Thereby, data security technologies should be applied to manage and secure the exchange and usage of the data. Based on the application scenarios, the MPC, ZKP, or TEE technology may be used to address the issue accordingly.
(1) Secure Multi-party Computation
Secure Multi-party Computation (MPC) is a cryptography-based distributed computing protocol and mechanism that dispenses with a trusted third party. Specifically, parties that do not trust each other in a distributed environment carry out coordinated computing using a cryptographic protocol and obtain the corresponding results. None of the parties can access any other information (including information such as the input and computing statuses) than the specific computing result returned to each of them. The MPC model is shown in the figure below, which serves to address the problem of multiple parties computing a function in a mistrusted environment.
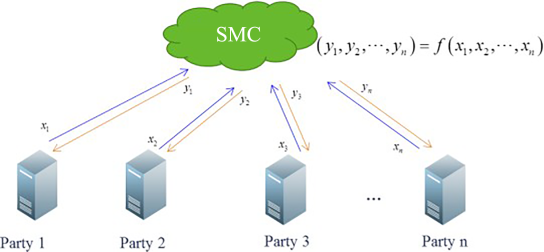
MPC Model
MPC computing protocols can be implemented by cryptographic means such as Garbled Circuit (GC), Secret Sharing (SS), and Homomorphic Encryption (HE). The MPC can be broken down into general MPC and special MPC according to the computing task involved. Theoretically, general MPC is complete and supports any computing task. However, special MPC protocols must be designed for specific computing tasks: Secure Comparison allows a party to obtain the comparison result but not the accurate input of the other party; Private Set Intersection (PSI) allows two parties to access only the intersection of their respective data set. Private Information Retrieval (PIR) allows a party to match and retrieve information pertaining to the target party in an anonymous manner with the target party unable to know the retrieval conditions and return results. In practical applications, the special MPC is commonly implemented due to its higher efficiency and the great computational complexity of the general MPC.
The privacy protection feature of MPC makes it applicable to querying vulnerability information in software supply chains. In a traditional vulnerability query scenario, a querying party submits the software name and version to the vulnerability management party who matches them to data in the vulnerability database to return vulnerability information. Or, in a software supply chain scenario, a customer (querying party) wishes to check whether its software product and related open-source components and referenced libraries contain any vulnerabilities. The customer wants to know whether the product contains any vulnerabilities and the details of the vulnerabilities without disclosing sensitive information (which can be regarded as SBOM information) to the vulnerability management party. With PIR, the software name can be encrypted on the client and then submitted to the server. After encrypting the vulnerability library, the server will conduct anonymous matching and retrieval. Similarly, the software version can be matched to information in the vulnerability library using Secure Comparison. By doing so, vulnerabilities in the software supply chain product can be queried with data privacy protected.
(2) Zero-Knowledge Proof
Zero-Knowledge Proof (ZKP) is another cryptography-based security technology, which can be applied to identity authentication and data verification. A ZKP allows the Prover (P) to convince the Verifier (V) that he/she has information X without providing any valid information to the Verifier or disclosing any other information about X during the process. Essentially, a ZKP is a security agreement between two or more parties, that is, a series of steps that the parties are required to take in order to accomplish a task.
According to the definition of ZPK, the following properties[2] are concluded:
a. Soundness. P is unable to deceive V. In other words, if the statement is false, no cheating P can convince an honest V that it is true, except with some small probability
b. Completeness. V is unable to deceive P. If the statement is true, an honest V will be convinced of this fact by an honest P.
c. Zero-knowledge. V is unable to access any additional knowledge.
A ZKP ensures the identity anonymity and privacy protection of both parties during identity authentication or transaction verification in a blockchain and digital currency system. Similarly, with ZKP technology, sensitive information such as SBOM and vulnerability data can be protected during use. For example, a software supply chain regulator wishes to check if the SBOM data of an installed software contains the version that has been notified for fixes. With a ZKP, the regulator can obtain the correct result (yes or no) while the sensitive information about the manufacturer that has installed the software is fully protected.
(3) Trusted Execution Environment
A Trusted Execution Environment (TEE) is a secure area built based on the hardware isolation mechanism. It guarantees code and data loaded inside the area are protected with respect to confidentiality and integrity. A TEE ensures that the hardware and software resources of a system are processed in two execution environments, namely the Trusted Execution Environment and the Rich Execution Environment (REE). The two environments are securely isolated and each has its independent computing and storage spaces. Applications in the REE cannot access the TEE. Even the applications within the TEE are independent of each other and cannot access one another without authorization. Before an external application is allowed to access the TEE, the application and the user identity are subject to verification. This makes sure that the confidentiality and integrity of the code and data inside the TEE are protected.
At present, the mainstream TEE technologies in the industry include Intel SGX, AMD SEV, ARM TrustZone, and Kunpeng processors. Intel SGX is suitable for PCs and servers and only supports a secure area of up to 128 MB. AMD SEV is only applicable to servers, but it covers the entire memory of a virtual machine, that is, a sufficiently large secure area. In addition, ARM TrustZone is mostly used for mobile devices.
Compared with the cryptography-based MPC and ZKP, the security of a TEE consists in its hardware isolation capability, avoiding considerable complex computations and interactions using cryptographic algorithms and protocols, along with additional computation and communication costs. Hence, TEE technology can be used for security protection in computing applications where a vast bulk of data must be protected or high performance is required. For example, the source code and data of a software supply chain can be migrated to a TEE to prevent them from tampering and unauthorized access, enabling high-level data security protection.
References:
[1] How Software Engineering Leaders Can Mitigate Software Supply Chain Security Risks
[2] Cao Tianjie, Zhang Yongping, Wang Chujiao. Security Protocol. Beijing University of Posts and Telecommunications Press, August 2009
Feel free to explore more posts in this Software Supply Chain Security series:
- Software Supply Chain Security: Overview
- Threats against Software Supply Chain Security
- The Increasing Trend of Software Supply Chain Attacks
- The Increasingly Complex and Varied Vectors to Attack Software Supply Chain
- Security Concept for Software Supply Chain (Part 1) — Transparency of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 2) — Assessable Capabilities of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 3) – Building Trusted Software Supply Chain
- Relationship Between Security Concept and Security Assessment for Software Supply Chain
- Technical Framework of Software Supply Chain Security
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 1)
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 2)
- Key Technologies for Software Supply Chain Security – Detection Techniques (Part 1) – Software Composition Analysis
- Key Technologies for Software Supply Chain Security – Detection Techniques (Part 2) – Static Application Security Testing (SAST)
- Key Technologies for Software Supply Chain Security – Detection Technique (Part 3) – Dynamic Application Security Testing (DAST)
- Key Technologies for Software Supply Chain Security—Detection Technique (Part 4)—Interactive Application Security Testing (IAST) and Fuzzing
- Key Technologies for Software Supply Chain Security – Data Security Technology
- Software Supply Chain Security Solution – Supply Chain Security Supervision (Part 1)
- Software Supply Chain Security Solution – Supply Chain Security Supervision (Part 2)
- Software Supply Chain Security Solution – Supply Chain Security Control