
Software supply chain security detection techniques must cover the software delivery life cycle, including software design, building, testing, and operation. There are mainly five types of security detection techniques, namely software composition analysis (SCA), static application security testing (SAST), dynamic application security testing (DAST), interactive application security testing (IAST), and FUZZ testing. Each of these detection techniques offers solutions to a specific stage of a software supply chain. The following table briefly introduces and compares these five types of techniques.
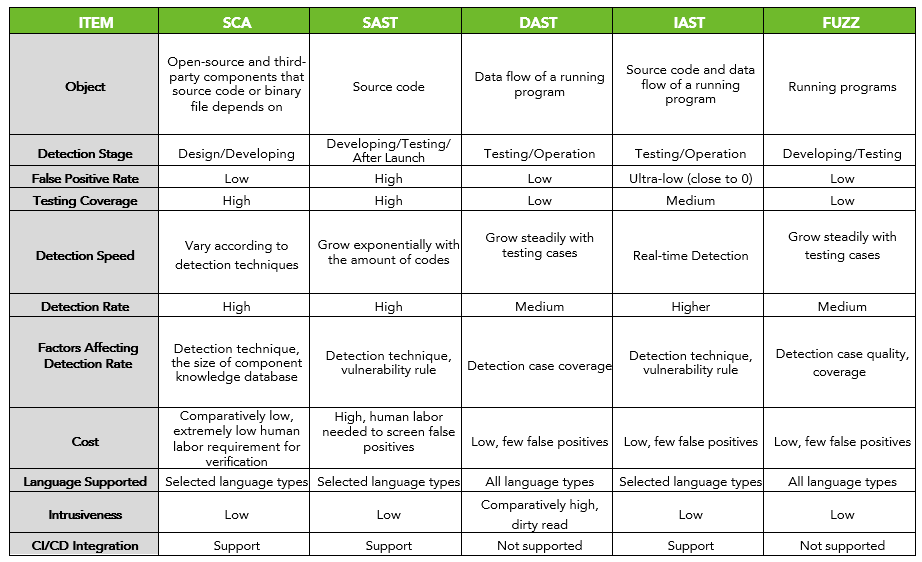
We will detail the five detection techniques one by one. Today we are focusing on software composition analysis.
Software Composition Analysis (SCA)
Open-source software is widely used in the software supply chain because of its openness, sharing, and freedom. Wider use of open code significantly improves the efficiency of software development and reduces its cost. However, open-source projects, often of uneven quality, are more exposed to attackers’ malicious tampering due to the existence of security vulnerabilities or maintenance personnel’s neglect to fix those vulnerabilities. This has posed a serious security problem. Today, with its number growing exponentially, open-source software is becoming more and more interdependent, resulting in huge difficulties in vulnerability identifying using human capabilities alone. Therefore, software composition analysis and vulnerability detection techniques are needed in order to solve this problem in an automatic and efficient way. Software composition analysis (SCA) is one of the most effective techniques of the kind.
SCA is a static, white-box detection technique, which automatically analyzes software’s source codes and binary files to identify its software bill of materials (SBOM) and detect vulnerabilities and compliance risks. Effective detection is the first step towards software security.
From a technical perspective, SCA is a general analysis method that is able to analyze any programming language including but not limited to Java, C/C++, Golang, Python, and JavaScript. It focuses on third-party artifacts composing software, and the dependencies between them. A single SCA process can be divided into four stages, namely source code/binary file analysis, feature extraction and identification, vulnerability detection, and SBOM generation.
1. Source Code/Binary File Analysis
SCA is featured by a high level of compatibility that works across programming languages. The programs on which SCA performs analysis can either be source code, or all types of compiled binary files. Moreover, SCA takes in various types of digital information regardless of its program architecture or compilation method. Its detection objects include class names, method/function names, constant strings, etc. on x86 platform or ARM platform as a windows program or a Linux program. The format of a binary analysis is as follows:
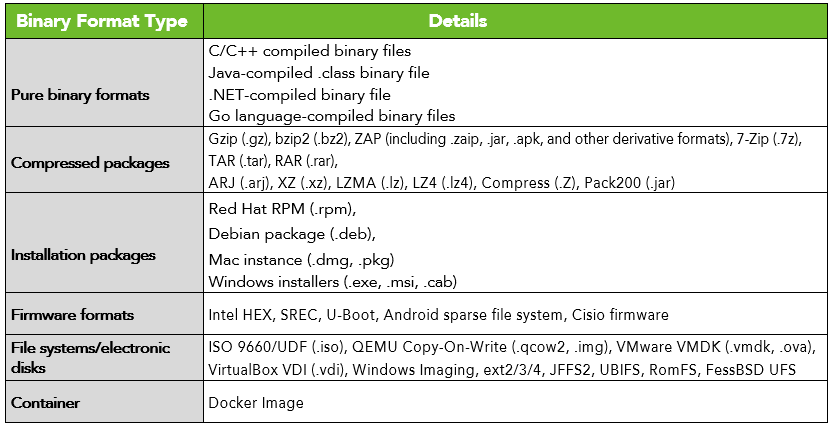
2. Feature Extraction and Identification
Component identification is the second stage of an SCA process, and it generally adopts two techniques: package manager parsing and fingerprint identification.
- Package Manager Parsing
SCA obtains information about the composition of certain software directly from package management configuration files in its source codes, such as requirements.txt in the Python project and package.json in the NPM project. Package manager parsing has high implementation effectiveness and efficiency, but might not be suitable for some scenarios. For binary files without a package manager or some binary files, SCA might miss out. C Language is one such example. There is no such thing as a package manager in C Language; instead, it uses source codes of open-source components in its own codes, resulting in the inability of SCA to identify those components. There could also be components without version definitions in some package managers. In this case, SCA is not able to determine the existence of vulnerabilities due to the lack of current version information. That’s why commercial software usually uses a combination of package manager parsing and fingerprint identification to improve identification coverage.
- Fingerprint Identification
The fingerprint identification system calculates the eigenvalues of an object file and matches them in the component feature database to identify a component. There are multiple commonly used algorithms to do the calculation; each has different accuracy and efficiency.
– Structural fingerprint identification analyzes the structure of a directory to generate fingerprints for similarity comparison, in this way it can identify open-source components.
– Fingerprint identification based on feature code is also used to identify open-source components. It does this by identifying features such as hash values or sizes of local files.
– Fingerprint identification through the code snippet slices a piece of code into fragments to generate a code fingerprint and identifies components through code fingerprint similarity comparison.
– Fingerprint identification through decompilation of binary code identifies components through similarity comparison.
– Fingerprint identification through string searching and customized fingerprint are used to identify components of closed-source software or third-party commercial software.
3. Vulnerability Detection
Vulnerability detection is the third stage of an SCA process; it matches identified components in the component vulnerability database to detect the existence of vulnerabilities and licensing risks, and offers solutions to customers.
4. SBOM Generation
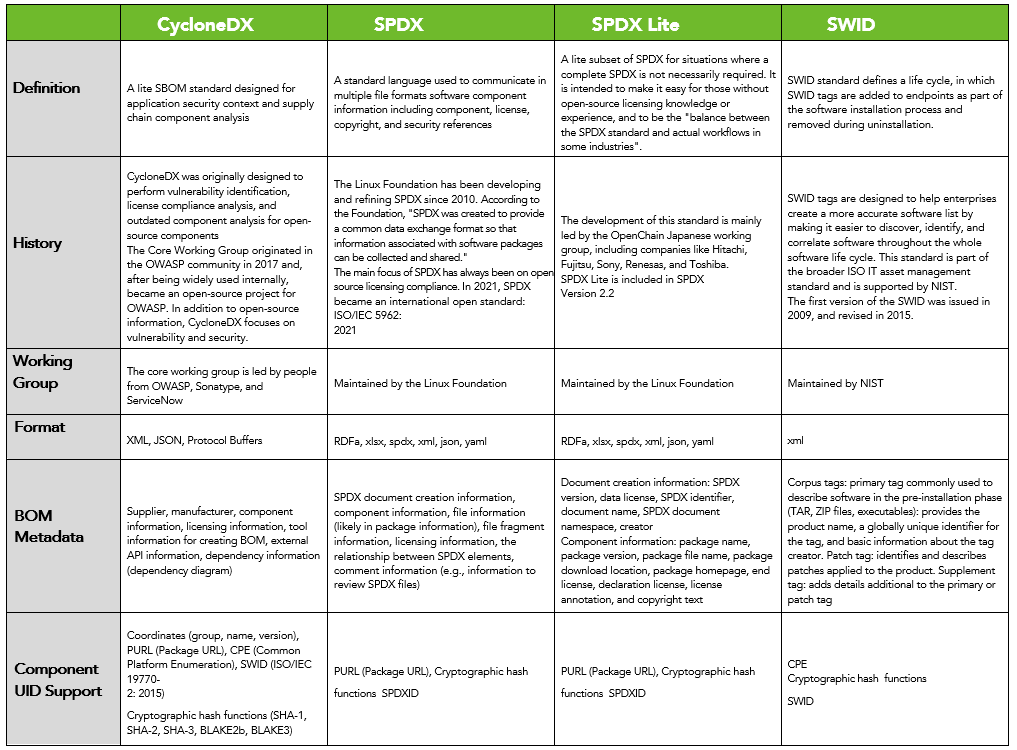
SBOM provides key information about the composition of and dependencies between components, vulnerabilities, and licensing. It is crucial for transparency in the software supply chain. There are currently three formats for implementing SBOM:
- SPDX: A grassroots effort from the Linux Foundation. The program is an open standard for communicating SBOM information, including components, licenses, copyrights, and security references.
- CycloneDX: designed specifically for security contexts and supply chain component analysis.
- SWID Tags: composed of files that record unique information about a software component and assist with inventory management initiatives.
In recent years, supply chain security problems caused by open-source components and third-party commercial software have been on the rise. Take the recent Log4j and SolarWinds intrusions for example, incidents like these have a great impact on general security due to their high availability and wide application. SCA technique does not require a program; instead, it analyzes the composition of third-party software in a static way to obtain knowledge graphs of the application’s components, which helps to improve the transparency of the software supply chain. Then it matches the components in the existing list of known vulnerabilities to help users fix problems in time.
Previous posts on software supply chain security:
- Software Supply Chain Security: Overview
- Threats against Software Supply Chain Security
- The Increasing Trend of Software Supply Chain Attacks
- The Increasingly Complex and Varied Vectors to Attack Software Supply Chain
- Security Concept for Software Supply Chain (Part 1) — Transparency of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 2) — Assessable Capabilities of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 3) – Building Trusted Software Supply Chain
- Relationship Between Security Concept and Security Assessment for Software Supply Chain
- Technical Framework of Software Supply Chain Security
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 1)
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 2)