RSA Conference 2019, an annual infosec event that brings all cybersecurity professionals together, kicked off in San Francisco, USA on March 4, 2019. This year’s Conference took “Better” as its theme, which reflected infosec players’ visions to constantly improve their own capabilities and work out better security solutions.
As usual, RSA 2019 covered a wide range of topics, among which the application of machine learning and artificial intelligence (AI) in the infosec field was still a much talked-about topic that attracted great attention. When discussing how to use machine learning to improve security predictions, Bugra Karabey, a senior risk manager from Microsoft, shared his idea of using machine learning as a cybersecurity analysis tool, in keeping with the current trend of applying machine learning to security analysis. Of all his proposed scenarios, “how to identify risk management process issues using PCA clustering” caught our eyes.

For large security incident databases, he constructed a dimensionality reduction model based on principal component analysis (PCA) clustering to produce security incident datasets and identify latent/dormant threats. As shown in the preceding figure, the implementation is mainly based on PCA and ggplot2 packages in R. Security incidents are subject to dimensionality reduction to form different datasets, or in other words, incidents are clustered according to behavior patterns. Based on these classified datasets, an experienced security analysis expert can perform a correlative analysis of risks or threats and finally discern unknown threats.
This is the new idea of applying machine learning to security analysis. Traditional rule-based security threat analysis is conducted on the basis of a known threat model built on known data. In the face of increasingly complicated and covert attack methods that result in a sharp rise in patterns to be analyzed, this model is limited, especially in “known unknowns” analysis that requires more than just rules. In contrast, machine learning has an obvious advantage in identification of unknown exceptions by building behavior baselines. However, exceptions detected against baselines produced by machine learning using various clustering algorithms or iterative learning of neural networks are Greek to customers. In other words, there is no clear clue for customers to understand what such unknown threats really mean to them. In this sense, machine learning, especially clustering analysis, is also limited. Therefore, it is necessary to combine the traditional rule-based analysis method with the modern machine learning before we see a real transition from the capability of analyzing “known knowns” to that of analyzing “known unknowns”.
NSFOCUS’s Application of Machine Learning
In this respect, NSFOCUS sees eye to eye with Microsoft. In the past years, NSFOCUS has been exploring ways to apply machine learning to security analysis. Now the idea of combining machine learning with rule-based analysis has taken shape and evolved into a unique threat analysis solution. The solution features a machine learning-enabled analysis engine, TURING, and a correlative analysis framework built on the TURING platform. This combines machine learning with rule-based analysis to implement intelligent reasoning and analysis of security threats, as part of our efforts to build an analysis platform that will gradually shift the focus from “known knowns” to “known unknowns”.
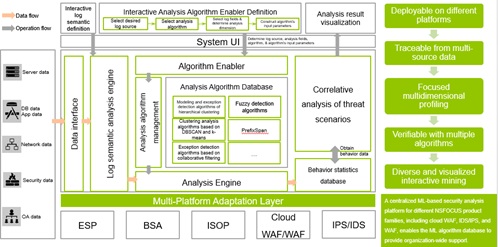
The TURING engine to be launched by NSFOCUS is supported by dozens of machine learning algorithms, including fuzzy reasoning, k-core, hierarchical clustering, decision tree learning, density-based spatial clustering of applications with noise (DBSCAN), k-means clustering, collaborative filtering, and isolation forest. Built on an algorithm-enabled framework, the engine leverages adaptive, iterative learning of multi-source data to establish host behavior and user behavior baselines for subsequent detection and analysis of anomalous behavior. The following figure shows the architecture of the solution.
Machine learning is a dynamic process. After the engine has been in use for some time, its centroids may be deviating. In addition, the improper size of data samples and the improperly configured clustering radius parameter or gradient will affect the accuracy of learning results (baselines), leading to overfitting or underfitting training results. For this reason, we provide an interoperability approach to constantly adjust the sensitivity of learning parameters, improve the learning accuracy via trust operations, and iterate deep learning, for the ultimate purpose of presenting behavior baselines that fit in with customers’ actual needs.

The algorithm database of the TURING engine contains three types of algorithms for different usage scenarios:
- Detection algorithms: Derive historical operation habits and baselines from historical data for subsequent matching of actions.
- Predictive algorithms: Infer future possible behavior from historical data to enable prediction and alerting.
- Relationship diagram algorithms: Identify potential connections between different sets of data through history learning to, for example, determine whether a process is anomalous based on its distribution in the network, and whether access is abnormal based on the host access relationship and user access relationship.
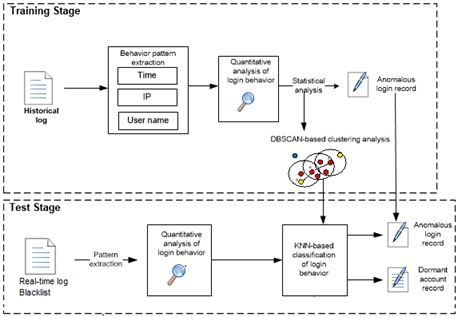
There is no clear boundary between algorithms and appropriate algorithms should be selected for specific scenarios. Take the identification of abnormal access for example. We use the login behavior as the centroid and extract user names, IP addresses, and time to form different pattern dimensions. Then a DBSCAN algorithm is used to cluster login behavior. For user names that belong to non-numerical and fully discrete patterns, we create a dictionary of user names based on semantic similarities to measure the Euclidean distance. Finally, login behaviors of similar patterns are clustered. The following figure shows the overall implementation process.
Laboratory tests have proved that the engine does work to our satisfaction. Besides, we used a customer’s real-life environment as a pilot office to test the effectiveness of the engine. Although the number of data samples was limited, the engine still detected such anomalous behavior as brute-force cracking, password leak, and frequent privilege escalation. The customer was also satisfied with the analysis results.
Powered by the preceding capabilities, the TURING engine of NSFOCUS boasts the following advantages:
- Has a trusted behavior database built on clustering and similarity modeling to enable identification of emerging threats that may be associated with known attack behavior or patterns, thus making up for the deficiency of rules for use in complex scenarios.
- For the ever changing and deviating business model, automatically conducts iterative learning to effectively reduce the daily chore of constantly adjusting rules and enhance the flexibility of detection in complex security scenarios.
- Has a built-in exception detection mechanism to identify illegal file uploads, illegal processes for planting backdoors, illegal file downloads, privilege escalation, abnormal login, and illegal file detections and modifications, covering key anomalous behavior of users in the behavior chain ranging from data leaks and breaches to advanced persistent threat (APT) attacks and various anomalous behaviors of hosts.
- Has an algorithm database that contains dozens of algorithm types to support security analysts’ interactive selection of data sources, selection of pattern dimensions, and selection of specific algorithms for iterative learning to create baselines.
- Supports cross verification with various algorithms and introduces a multi-algorithm decision mechanism to improve the detection accuracy and lower the rate of false positives.
- Can be deployed on different platforms to work with a variety of products for threat analysis.
After an exception is detected by the TURING engine, a Flink-based framework launched by NSFOCUS for correlative analysis of security threats can be used for temporal correlation of various security threat scenarios from the perspective of hosts or users to deliver human-readable user security threat scenarios or host security threat scenarios.
Business Scenarios Supported by the TURING Engine
Currently, the TURING engine comes with support for such security analysis scenarios as data leaks, data breaches, anomalous user access, anomalous access between intranet business processes, presence of portable storage devices and copy of sensitive files, exfiltration through covert channels, and various APT attacks, including credit card information thefts, cryptomining that consumes large amounts of computing resources, Stuxnet attacks, Operation Aurora, and watering hole attacks. Go on reading and you will get a glimpse of how the TURING engine works for different security analysis scenarios.
-
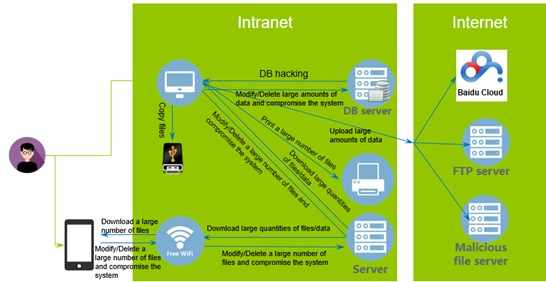
Intranet data leaks/breaches
Usually, when perimeter protections are complete, what worries customers most in security is the failure to effectively detect lateral attacks, data leaks, and data breaches in intranets.
To address this issue, NSFOCUS has developed the TURING engine that can leverage user names, IP addresses/segments, periods of time, file types, file sizes, and file paths obtained from raw historical data to establish file upload, download, and deletion/modification baselines with different machine learning algorithms. Then the engine can detect exceptions against these baselines and generate related information. In cooperation with the correlative analysis framework, the engine can visualize the result, showing whether a user is stealing or breaching data or a host is suffering a data theft or breach.
-
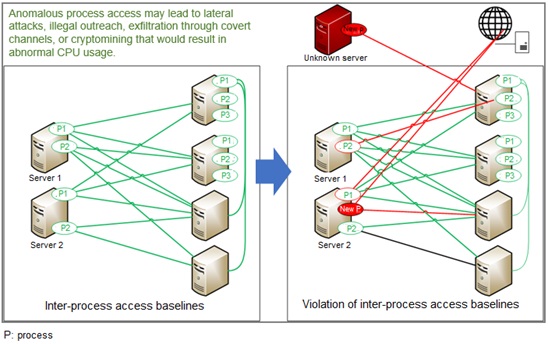
Anomalous inter-process access in the intranet
Anomalous inter-process access in an intranet could lead to lateral attacks, illegal outreach, exfiltration through covert channels, or Bitcoin mining that results in exorbitant CPU usage. This is usually achieved via some illegal backdoor software installed on a compromised host on the intranet.
The TURING engine, based on process running logs provided by servers and hosts, uses machine learning algorithms to establish a baseline of access relationships between a process and other hosts, CPU usage baseline, memory usage baseline, and data usage baseline. When an illegal process is launched for persistent residency and attempts lateral attacks, outreach, exfiltration through covert channels, or cryptomining that results in abnormal CPU usage, it will be on the TURING engine’s radar.
-
APT attack scenarios: cryptomining that consumes computing resources
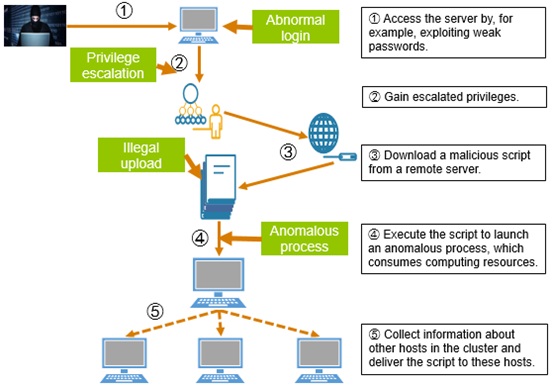
In the past several years that have witnessed the rapid development of the blockchain economy, viruses and trojans targeting cryptocurrency have sprung up like mushrooms. The prevalence of cryptominers leads to exorbitant usage of computing resources, greatly impeding the normal provisioning of services. As it is costly for defenders to counter this type of attacks, which is, however, lucrative for attackers to launch at low costs, cryptomining that hijacks computing resources has steadily risen. The cryptomining kill chain runs as follows:
- Access the server by, for example, exploiting weak passwords.
- Gain escalated privileges.
- Download a malicious script from a remote server.
- Execute the script to launch an anomalous process (if it is for cryptomining, a large proportion of computing resources will be used).
- Collect information about other hosts on the network.
- Deliver the malicious script to these hosts.
The TURING engine can capture such key anomalous behavior as abnormal login, privilege escalation, illegal upload, anomalous process running, and abnormal CPU usage before presenting the entire anomalous behavior chain from the perspective of users.
-
APT attack scenarios: Stuxnet attack
Stuxnet is a malicious computer worm. It is so sophisticated as to be far beyond the capacity of ordinary computer hackers. First uncovered in June 2010, Stuxnet is believed to be a worm specially used for targeted attacks against real-world infrastructure (energy) like nuclear power plants, dams, and state grids.
It exploited four vulnerabilities in Microsoft Windows that had never been discovered before. It uses a USB flash drive of some insider to enter an intranet system, and then uses other exploits to penetrate the private network before infecting other hosts on the intranet. This is what traditional attacks can hardly achieve.
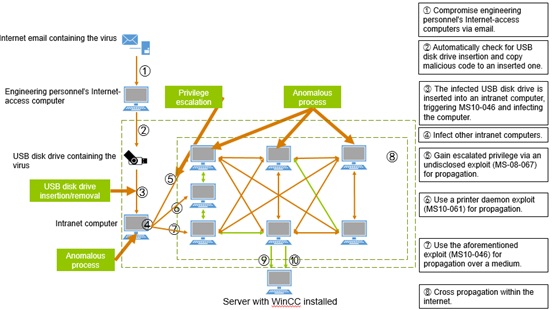
The kill chain of the Stuxnet attack runs as follows:
- Compromise engineering personnel’s Internet-access computers via email.
- Automatically check for the presence of USB disk drives.
- Copy malicious code to such a USB disk drive.
- The infected USB disk drive is inserted into an intranet computer, triggering the MS10-046 vulnerability.
- Infect the computer and then other computers on the same intranet.
The TURING engine can capture such key anomalous behavior of Stuxnet attacks as USB disk drive insertion and removal, copy of files to a USB disk drive, anomalous file upload, anomalous process running, and anomalous process running on other hosts before presenting the entire behavior chain from the perspective of users.
- APT attack scenarios: Operation Aurora
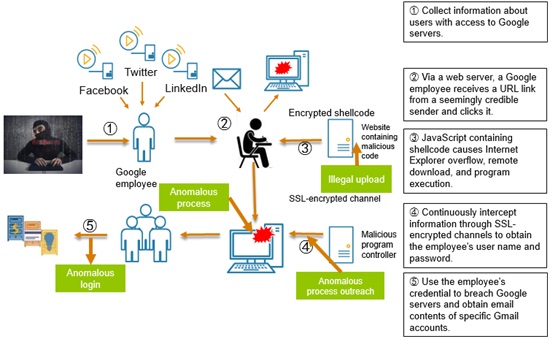
Operation Aurora was a series of organized cyberattacks taking place in mid-December 2009. The initial attack was triggered by a Google employee who clicked a malicious link in an instant message. Subsequently, a series of events ensued, causing the network of the search engine giant to be penetrated for several months. As a result, data of various systems was stolen. This operation targeted Google and twenty-some other companies. It was carefully schemed by an organized criminal group for the purpose of penetrating these enterprises’ networks to steal data.
The TURING engine can capture key anomalous behavior like those found in Operation Aurora, including illegal upload, anomalous process running, anomalous process outreach, and anomalous login, before presenting the entire behavior chain from the perspective of users or hosts to facilitate security analysts’ further analysis and response.
Epilog
The TURING engine is an initial fruit of our efforts to apply machine learning to security analysis. With the rapid development of AI technologies as well as the adoption of machine learning and neural network technologies in the cybersecurity field, we believe that in days to come more AI technologies will find their way into the infosec realm. But what we should keep in mind is that AI and the underlying machine learning algorithms are neither a magic wand nor a crystal ball. That AI algorithms will take over all security analysis work is just a wishful thinking. A practical approach is to combine them with security experts’ experience. Only in doing so can we bring machine learning into full play.