
Compliance has seen radical changes in the requirements and driving force of data security and a broader category of data objects under data security protection. Application scenarios covered by data security will become more diversified, and data security requirements will cover all phases of the data lifecycle. In order to better cope with the challenges posed by compliance, enterprises need to transform from traditional single-point development to systematic data security development.
In this post, we are going to talk about security of data sharing, storage, and analysis.
Release and Sharing of Personal Data
Individuals’ privacy needs to be protected during release and sharing of personal data.
- GDPR Compliance Requirement
Enterprises cannot directly share raw personal data. However, they can conduct statistics and research on pseudonymized personal data without being bound and restricted by GDPR (Paragraph 26 in General provisions).
- Problem and Challenge
It is challenging for enterprises to achieve cost-efficient, secure, and compliant sharing and release of personal data.
- Solution: Data anonymization
Secure Storage and Computing of Data on Clouds
When uploading sensitive data to public clouds for storage and computation, enterprises need to guarantee that third parties cannot steal private information.
- GDPR Compliance Requirement
It is recommended that encryption and other technical measures should be taken to respond to security risks in data storage and processing (Article 32).
- Problem and Challenge
Further analysis cannot be performed on the data encrypted via traditional data encryption methods, such as AES and 3DES. A new type of encryption technology is required to guarantee that data is secure and data can still be processed after being encrypted.
- Solution: Homomorphic encryption
Secure Sharing and Computing of Multiparty Data
Various parties hold different sensitive data and aggregate and compute multiparty input data under the premise of ensuring data security.
- GDPR Compliance Requirement
It is recommended that encryption and other technical measures should be taken to respond to security risks in data storage and processing (Article 32).
- Problem and Challenge
Traditional sharing and computing of multiparty data require various parties to upload their own sensitive data to servers for computing. Nevertheless, this solution still faces the problem of privacy theft by third parties. A “decentralization” solution needs to be presented.
- Solution: Secure multiparty computation
Joint AI Modeling of Multiparty Data Security
Multiple enterprises make joint efforts in AI modeling but hope that sensitive information and private data will not be disclosed in AI training and modeling.
- GDPR Compliance Requirement
It is recommended that encryption and other technical measures should be taken to respond to security risks in data storage and processing (Article 32).
- Problem and Challenge
Traditional distributed machine learning is primarily used to solve computation bottlenecks and cannot guarantee the security of input data and privacy.
- Solution: Federated learning
The technologies for the solutions above are illustrated below.
Data Anonymization
Data anonymization is to generalize and shield personal information so that the corresponding personal information subject cannot be identified and the effect of “anonymization” is achieved.
K-anonymity is the first to be proposed among anonymization technologies[i]. It can ensure that at least K records in a data table are generalized to the same value. This ensures certain data availability and protects patients’ privacy. Even if the attackers command background knowledge, they cannot uniquely determine which record belongs to a friend’s diagnostic record.
Since K-anonymity does not restrict sensitive attributes, when the sensitive attributes of the equivalence groups have the same value, there are still privacy risks. Later, scholars proposed L-diversity[ii] and T-closeness models[iii].
- L-diversity model: It can ensure that the formed equivalence groups contain at least K records and the sensitive attributes of any equivalence group contain at least L different values by modifying sensitive attributes or adding forged records.
- T-closeness model: It can ensure that the formed equivalence groups contain at least K records and the distance measurement between the distribution of sensitive attributes of any equivalence group and the distribution of global sensitive attributes is smaller than the parameter T by modifying sensitive attributes or adding forged records.
Generally speaking, in terms of the privacy protection degree and effect, T-closeness is better than L-diversity, which is better than K-anonymity. However, as for data availability, it is the other way around. In actual application scenarios, technologies should be selected according to the specific requirements for privacy and availability.
Homomorphic Encryption
The concept of homomorphic encryption (HE) was first proposed by Rivest et al. in 1978[iv]. It is a special encryption algorithm, and its formalization can be expressed in this way: assuming that A and B are two plaintexts to be encrypted and Enc(-) is the encryption function, then there exists the following relationship (called mathematical homomorphism):
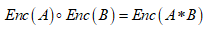
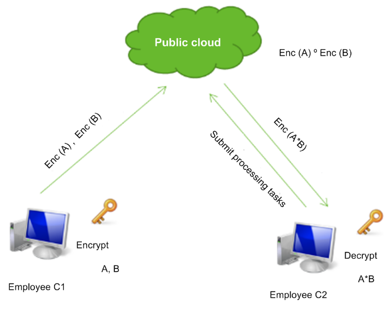
Simply put, performing the “o” operation in the ciphertext domain is equivalent to performing the “*” operation in the plaintext domain (“o” and “*” are two specific mathematical operations). This property makes it possible to perform data processing, analysis, and retrieval operations in the ciphertext domain. Besides, this method is especially useful for securing cloud computing. A simple example: As shown in the following figure, in an untrusted cloud environment, the employee C1 uploads two pieces of ciphertext data Enc(A) and Enc(B) to an untrusted cloud platform, the employee C2 submits two pieces of ciphertext data for the * task, and then the execution of the data translated by the public cloud platform is: the ciphertext operation Enc(A)oEnc(B). Since the data is encrypted from beginning to end, neither cloud service providers nor attackers are able to access or steal the plaintext data, thus ensuring data security on the cloud platform.
According to the ability of homomorphic encryption, homomorphic encryption is divided into additive homomorphic encryption (AHE), multiplicative homomorphic encryption (MHE), and full homomorphic encryption (FHE). FHE can satisfy both AHE and MHE and perform any mathematical operation, and is so widely applicable. In 2009, Gentry, an IBM researcher, proposed for the first time a complete FHE scheme[v]. However, research showed that the Gentry scheme had a high computational cost, a large key size, and a large ciphertext size. Subsequently, some improvement solutions were put forward, such as BGV, Learning with Errors (LWE), Ideal Coset Problem (ICP), and Approximate Greatest Common Devisior (AGCD).
Secure Multiparty Computation
In fact, secure multiparty computation (MPC) can be regarded as a special computation protocol involving multiple nodes: In a distributed environment, various participants perform collaborative computing without trusting each other, output computation results, and guarantee that neither party can get any other information except the due computation results, including information such as input and the status of the computing process. MPC ensures data security in a distrust environment where multiple participants jointly compute a function[vi]. To elaborate on the principle, the following figure shows the difference between MPC and traditional distributed computation.
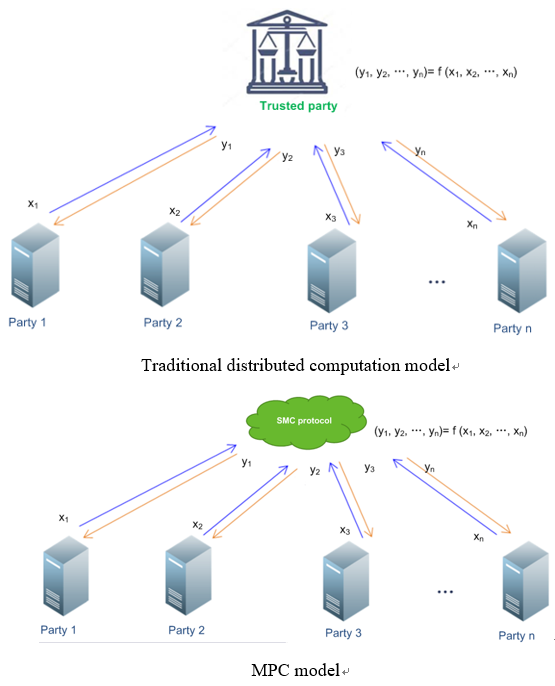
MPC has the following characteristics:
- Privacy: Participants can only obtain their own input and output data.
- Correctness: MPC can ensure that all participants can get correct computation results after joint computation.
- Decentralization: Different from traditional distributed computation, MPC provides a decentralization mode in which various participants have an equal footing and there are no privileged third parties.
Protocols for MPC are mainly based on garbled circuit (GC), secret sharing (SS), and homomorphic encryption (HE). According to supported computing tasks, MPC can be divided into two types: MPC in dedicated scenarios and MPC in general scenarios. MPC in dedicated scenarios supports specific computing tasks, such as comparing numerical values and use of private set intersection (PSI) to compute the intersection. Theoretically, MPC in general scenarios can support any computing task and is more inclusive.
Federated Learning
The concept of federated learning (FL) was first proposed by Google in 2016[vii] and was originally used to solve privacy problems in large-scale collaborative distributed machine learning on Android devices. As an emerging technology, FL integrates machine learning, distributed communication, and privacy protection technologies and theories.
With the strengthening of global privacy regulations and the strong demand for data utilization, since the concept of FL was put forward, it has received widespread attention from both academia and industry and has developed rapidly. It can not only be applied to 2C scenarios, such as user mobile devices, but also has been extended to 2B scenarios, such as sensitive data sharing and machine learning between enterprises. FL allows multiple participants (such as enterprises and user mobile devices) to combine machine learning modeling, training, and model deployment without exchanging raw data. In simple terms, FL is a distributed machine learning framework and algorithm that can protect privacy.
According to different scenarios in which participants use datasets, FL is divided into three categories: horizontal federated learning, vertical federated learning, and migrated federated learning. In horizontal federated learning, various parties use different datasets with the same sample dimensions and different sample IDs. In vertical federated learning, various parties use datasets with the same sample IDs and different sample dimensions. In migrated federated learning, various parties use datasets, of which only a small number of sample IDs and sample dimensions overlap.
The core idea of federated learning is to implement multiparty data sharing and joint modeling while ensuring that the raw data is not transmitted out of the local domain. If the raw data involved in multiparty modeling needs to be converted, FL first characterizes and parameterizes the data to ensure “invisibility”. Besides, FL applies differential privacy, homomorphic encryption, or secure multiparty computing technology to feature vectors and parameters to avoid privacy leakage caused by training reconstruction attacks and model inversion attacks.
The series of four articles aim to sort out and analyze compliance requirements in data security scenarios for enterprises, i.e. security and compliance of user privacy data, data security governance within enterprises, and data sharing and computing between enterprises. It carries out research and analysis on 10 cutting-edge data security technologies that the industry can deal with, including differential privacy (DP), data anonymization, homomorphic encryption (HE), secure multiparty computation (MPC), federated learning (FL), and other new technologies introduced from other fields, such as knowledge graph, process automation, and user and entity behavior analytics (UEBA). Through the research on these technologies, we hope to find inspiration and ideas for breakthroughs in new security scenarios and empower enterprises to solve the pain points and difficulties of data security and compliance.
[[i]] Sweeney L. K-anonymity: A model for protecting privacy. International Journal of Uncertainty, Fuzziness and Knowledge-based Systems, 2002,10(5):557-570.
[[ii]] Machanavajjhala A, Kifer D, Gehrke J, et al. L-diversity: privacy beyond k-anonymity. ACM Transactions on Knowledge Discovery from Data, 2007, 1(1):3.
[[iii]] Li N H, Li T C, Venkatasubramanian S. T-Closeness-privacy beyond kanonymity and l -diversity. IEEE 23rd International Conference on Data Engineering, Istanbul, Turkey, April 15-20, 2007: 106-115.1
[[iv]] Rivest R., Adleman L., Dertouzos Venue M. On Data Banks and Privacy Homomorphisms. 1978.
[vi]] RashidSheikh, DurgeshKumarMishra, BeerendraKumar. Secure Multiparty Computation: From Millionaires Problem to Anonymizer. Information Systems Security, 2011, 20(1):25-33.
[vii] Mcmahan H B, Moore E, Ramage D, et al. Communication-Efficient Learning of Deep Networks from Decentralized Data. 2016.