The security knowledge graph, a knowledge graph specific to the security domain, is the key to realizing cognitive intelligence in cyber security, and it also lays an indispensable technological foundation for dealing with advanced, continuous and complex threats and risks in cyberspace. NSFOCUS will publish a series of articles about the application of the security knowledge graph in several scenarios. This article focuses on the technologies related to the graph construction for advanced persistent threat (APT) groups, to help track APT groups.
Introduction
As the attack surface in cyberspace continues to expand, malicious attackers tend to be large-scale and organized, and APT attacks are increasingly frequent, tending to be regular. APT attacks often have clear attack intentions with highly stealthy and latent attack methods, posing a major threat to important government and enterprise assets. Since the information data involved in APT threat analysis and source tracing is chaotic and self-contained, it is hard to organize effectively, resulting in heavy manpower consumption in the event analysis process, and failure to save the relevant expert knowledge to form a reusable knowledge base. By defining domain knowledge, the knowledge graph technology allows logically associating random knowledge using the Semantic Web, which can help arrange information security knowledge in a systematic manner and convert expert knowledge into machine language. Therefore, cyber security researchers have gradually begun to use knowledge graphs for threat analysis and source tracing.
Construction of the APT Group Graph
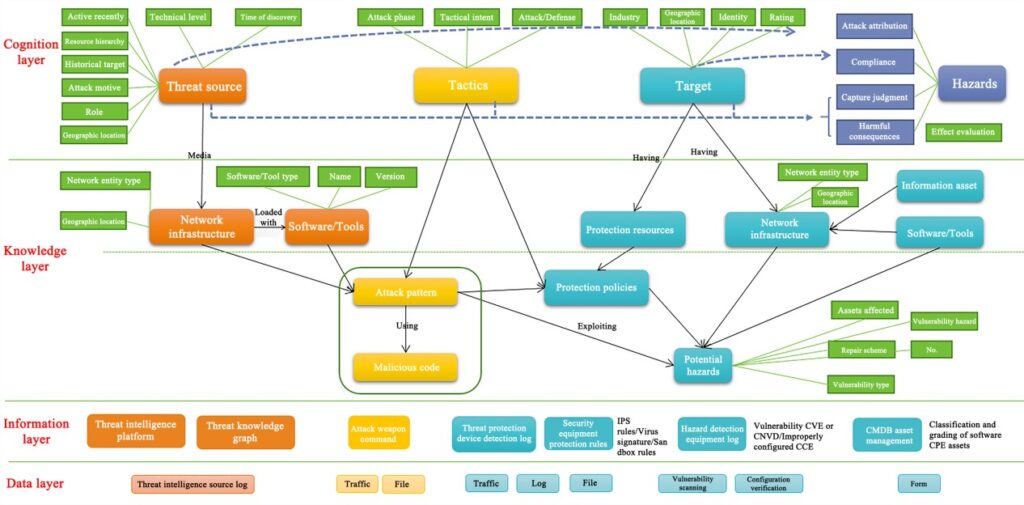
The APT group knowledge graph, with the attack group (APT, malicious code family, etc.) at its core, can show the composite portrait of the ATP group based on analysis of the technical level of the group (attack tools, attack methods, mastered vulnerability exploits, and malware), network infrastructure (IP address, domain name, and email), historical campaigns, features of attack targets, as well as hazards and intentions. NSFOCUS mainly refers to relevant specifications in the security domain for various security entities targeted by attack groups, and the STIX 2.0[1] description language is mainly used for the design of relationships between the entities. The threat metalanguage system built consists of 4 layers, 11 main entity types, and millions of knowledge vertices. Figure 1 shows the ontology finally built.
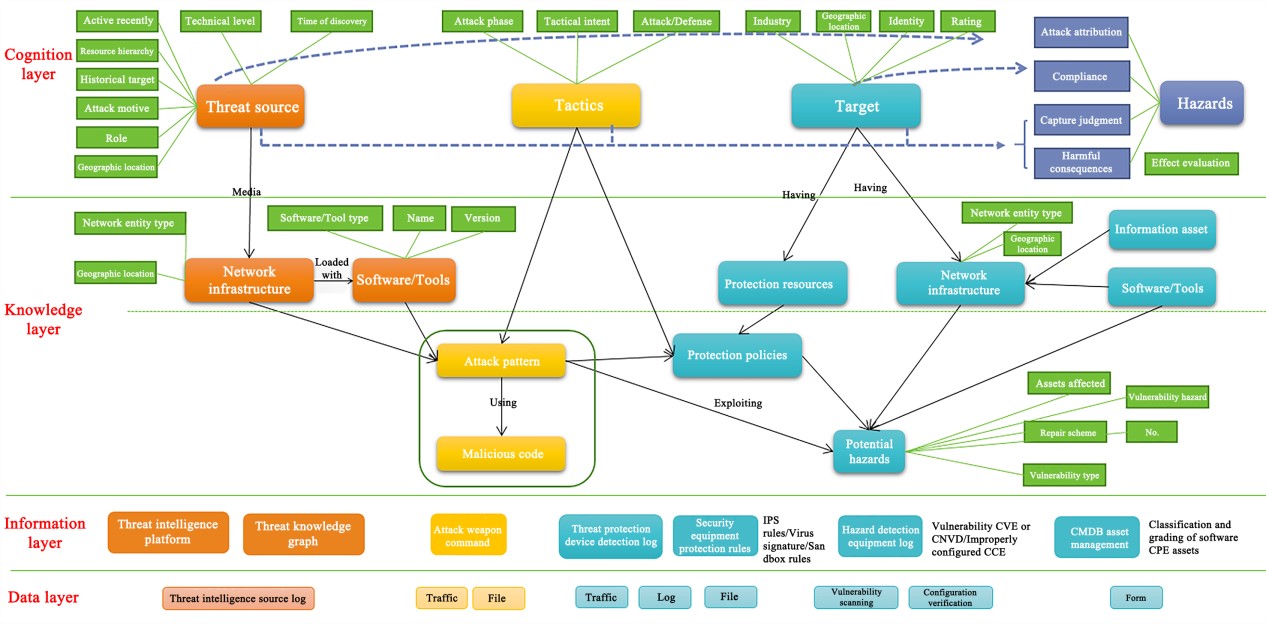
The EternalBlue vulnerability in the NSA’s cyber arsenal is taken as an example. Specifically, the threat subject is NSA, the attack tool is Metasploit, the attack pattern is the EternalBlue vulnerability attack, and the vulnerability is CVE-2017-0143. Moreover, the protection methods include port closure and traffic drop, and the attack target is the Windows 7 operating system. In the actual business scenario, the analyst only needs to detect a certain threat entity in the knowledge graph, such as the SMB remote code execution vulnerability (CVE-2017-0143). By establishing the semantic relationship of the knowledge graph (weakness_of and defensed_by) and analyzing the relationships between information assets (like servers, firewalls, and routers) in actual business scenarios, the graph can output the list of affected assets (servers), and offer risk handling suggestions (closing port 445 or dropping traffic), which helps obtain situation information and further reason out the impact scope and available defensive measures. Figure 2 shows the association relationship.
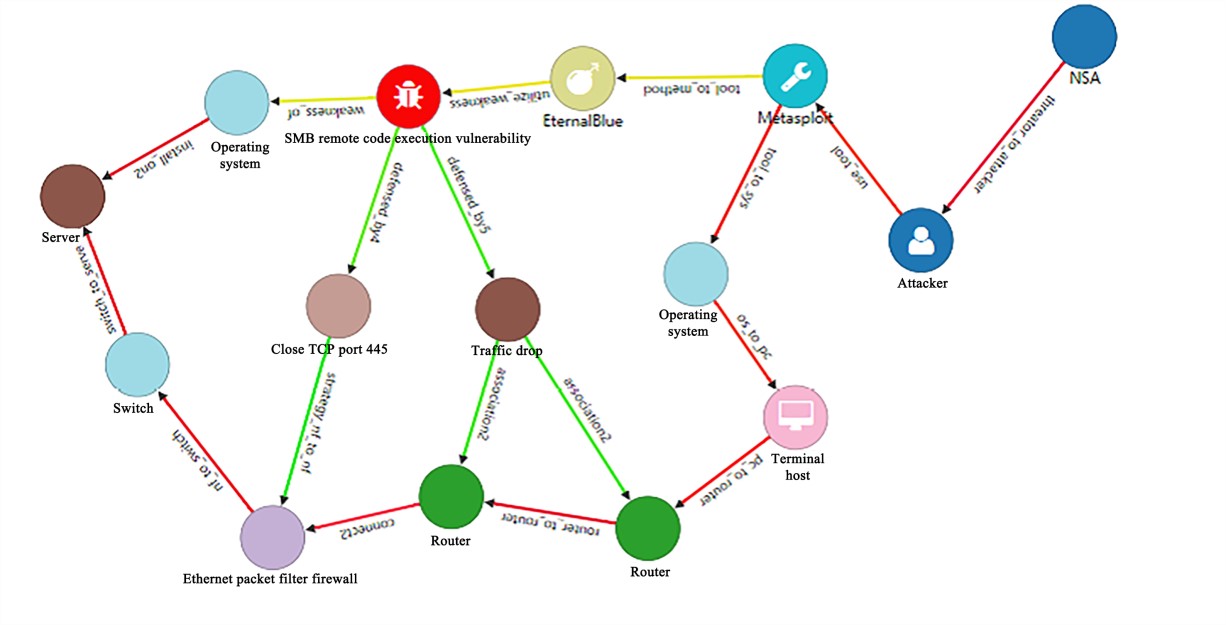
At present, a large amount of advanced threat intelligence exists in unstructured text information, and a highly extensible intelligence source needs to be configured based on the intelligence source configuration template, to filter attacker-related intelligence and eliminate irrelevant data. Figure 3 shows the intelligence collection process using the natural language processing (NLP) technology and template-based crawler, which mainly includes raw intelligence collection, intelligence topic distinction and automatic extraction of threat intelligence. The raw intelligence collection module mainly configures data sources, selects the corresponding template to input the specified configuration items for debugging, generates the crawler file, and improves the crawling performance of the crawler with middleware, thus enabling fast and highly compatible crawling, and exporting structured data and unstructured original report files (HTML files). Since the data collected from the data source may contain recruitment information, product promotion information, etc. published by websites/we-media, the unstructured data (HTML files) needs to be distinguished between different topics, which can facilitate subsequent intelligence extraction. Adopting the topic classification method based on Jieba word segmentation, the intelligence topic distinction module extracts text after parsing the HTML files, further associates the extracted text with the self-built dictionary, and classifies the text into three categories: APT attack groups, malicious code families, and others. The threat intelligence automatic extraction module inputs the original report, cleans and echos the hidden threat intelligence in the text sample using a normalized text cleaner, and extracts the threat intelligence using targeted regularization and named-entity recognition (NER) technologies. The extracted intelligence includes network addresses, domain names, links, vulnerabilities, attack techniques, and sample hashes. Then, it employs the NLP technology to identify attackers, software tools, geographic information, attack targets and other information, and finally outputs the formatted threat intelligence data.
Conclusion and Outlook
With the explosion of cyberspace confrontation data and the increase in technical complexity, APT attacks become increasingly difficult to detect. The key to the accurate description of different APT groups is to establish a unified language to describe the behaviors and features of different APT groups, build a knowledge base about APT groups, and continuously use and expand the knowledge base. At present, the scheme of manual graph construction is laborious, and the constructed graph is small and less applicable. Therefore, given the confrontation nature of cyber attacks and defenses, an ontological, standardized and globalized knowledge structure needs to be designed for the network environment data, threat behavior data, threat intelligence data and security knowledge base. Compatible with the existing standards and architectures, it allows selecting the appropriate scope of knowledge in actual application scenarios. Moreover, it can autonomously obtain and process information from massive multi-source heterogeneous cybersecurity data using AI technologies combined with the participation of security experts, automatically extract security knowledge in batches by machine, complete relationships using the knowledge representation and knowledge reasoning model, and intelligently build a security knowledge graph, thus laying a foundation for the application of APT attack analysis in large dataset scenarios.
References
Oasis group. Stix 2.0 documentation. https://oasis-open.github.io/ cti-documentation/stix/examples.html, May 2013
Posts About Security Knowledge Graph
Technologies and Applications of the Security Knowledge Graph