
The Governance, Risk & Compliance track of the RSA Conference 2019 focuses on quantification of cybersecurity risks and related cases. For example, Superforecasting II: Risk Assessment Prognostication in the 21st Century by Rich Howard from Palo Alto Networks dwells upon how to evolve semi-quantitative risk assessment into more accurate quantitative risk assessment; Math is Hard: Compliance to Continuous Risk Management presents the entire process of quantitative risk assessment; NIST Cybersecurity Framework and PCI DSS provides practices of implementing PCI-DSS standards in the cybersecurity framework (CSF) and points out complex mapping relationships between the two.
The current compliance and risk governance area is mainly faced with the problem of unstructured and semi-structured documents being unable to be efficiently converted to quantitative data, which results in ineffective assessment of managerial information during risk management. To address this problem, Bugra Karabey, senior risk manager of Microsoft, proposed introducing machine learning tools into cybersecurity risk management. The general idea is to use natural language processing (NLP) to parse unstructured documents and extract key information of documents, and at the same time use a particular dimensionality reduction algorithm for risk identification.
Bugra Karabey first described the current state of cybersecurity risk management:
(1) Results of subjective risk evaluations based on subject matter expert interviews are hard to quantity.
(2) Limited data-driven risk assessment methodologies yield limited results.
(3) Analysis is based on qualitative rather than quantitative data points.
(4) A 5-point grading scale is used to quantify the impact and likelihood of risks.
(5) The focus is on known risks.
Besides, Bugra Karabey pointed out that machine learning is already ubiquitous in cybersecurity for log, telemetry, and traffic pattern analysis, anomaly detection, and behavior analytics. However, for the identification and assessment of dormant/latent risk themes, patterns, and relationships, additional machine learning tools will be useful for the following reasons:
(1) The insights reside within text-heavy datasets (security policy exceptions, internal and external incidents, and Governance Risk Compliance (GRC) security findings).
(2) Natural language-driven machine learning is required for risk assessment.
(3) Artifacts may be at the board room discussion level, rather than technically focused.
He also described how to apply machine learning to cybersecurity risk management in three scenarios.
-
Identifying Top Risks Using Topic Modeling
Topic modeling is a statistical model for discovering abstract “topics” and discovery of a group of words that collectively represent a topic in a large collection of documents. Most popular topic modeling techniques are Latent Semantic Analysis (LSA) and Latent Dirichlet Allocation (LDA). The following figure shows the process of identifying top risks using topic modeling.
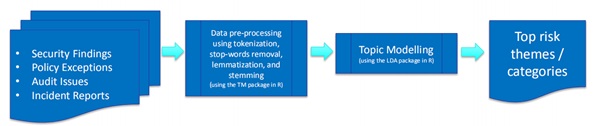
(1) Collect text-heavy documents related to cybersecurity, including security findings, policy exceptions, audit issues, and incident reports.
(2) Conduct data preprocessing, including stop-words removal, lemmatization, and stemming.
(3) Proceed to topic modeling (LDA/LSA).
(4) Identify high-risk themes/categories.
Bugra Karabey suggested using machine learning tools to perform steps 2 and 3. In step 2, the TM package in R can be used for natural language processing. In step 3, the LDA package in R can be used for topic modeling.
From the abstract topics discovered using the preceding process, we can obtain risk factors (fabricated data).
-
Identifying Latent/Emerging Risks Using NLP
Bugra Karabey uses two methods to identify latent/emerging risks: word embeddings and LSTM (long-short term memory) Deep RNNs (Recurrent Neural Nets).
2.1 Word Embeddings
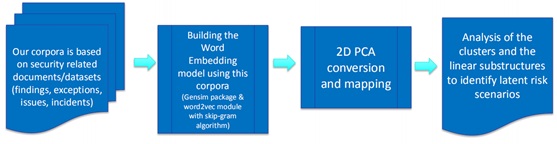
Word embedding is a process of converting a word into a fixed-length vector representation and aggregating words of the same nature by means of training. The detailed process is as follows:
In step 2, the gensim package and the skip-gram algorithm of word2vec can be used for building the word embedding model.
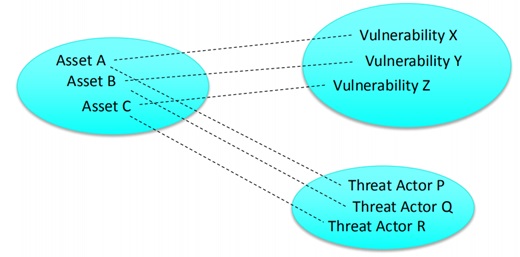
Take assets for example. By analyzing the word embedding space (reduced to 2D or 3D), the user can identify the relationships between assets, actors, and vulnerabilities.
2.2 LSTM Deep RNNs
LSTM-RNN is a particular type of RNN to mitigate long-time lag problems of RNN. The main idea behind it is to introduce cells and linear connections that enable RNNs to save and export historical information selectively. The following figure shows the process of identifying cybersecurity risks using LSTM.
In step 2, Keras (with Tensorflow or CNTK as the backend) can be used for building the LSTM RNN model.
A user enters seed phrases into the established model, which generates outputs for risk analysis. Following is a sample:

-
Identifying Risk Management Process Issues Using PCA Clustering
Principal component analysis (PCA) is a dimensionality reduction algorithm whose core lies in the projection of n-dimensional features onto the k-dimensional space, a principal component that is a new orthogonal basis for feature space. It is a process of reconstructing k-dimensional features based on the original n-dimensional ones. This algorithm retains only feature dimensions that contain most variances while ignoring those with nearly zero variances, thereby reducing data dimensions.
The following figure shows the process of identifying cybersecurity risks using PCA.

In step 2, PCA and ggplot2 packages in R can be used for 3D PCA.
As shown in the following figure, incidents are clustered in three sets, which may indicate a certain pattern (with an underlying root cause to be investigated) in incident occurrences.
-
What to Conclude and Expect
The USA adopts the Federal Information Security Modernization Act (FISMA) as the core of its governance system. From FISMA 1.0 to FISMA 2.0, the US government has shifted its focus to continuous monitoring and integration of cybersecurity into the overall design rather than remediation after incidents. FISMA 2.0 prioritizes continuous, ongoing monitoring of federal networks over departments’ and agencies’ development of static, file-based compliance reports. To meet the requirements of FISMA 2.0 for quasi-real-time monitoring, the National Institute of Standards and Technology (NIST) developed the Cybersecurity Framework (CSF), which, in combination with the Security Content Automation Protocol (SCAP) and Open Security Controls Assessment Language (OSCAL), implements automated monitoring and response technically and managerially in line with different system security standards.
By referring to CSF and using modeling languages, NSFOCUS has developed a critical information infrastructure governance architecture. This architecture, with a threat knowledge atlas at the core, projects structured threat data (security logs and traffic data) onto knowledge entities on the atlas for threat analysis and alerting based on expertise. In addition, it manages dimensional data, for example, by converting provisions of classified information security protection regulations into knowledge entities, to correlate technical information with managerial information by using reasoning provided by the atlas.
Such a governance architecture requires continuous input of technical and managerial data to achieve ongoing monitoring of risks. However, as unstructured or semi-structured security documents (audit reports, security incident reports, and the like) cannot be efficiently and automatically translated into machine-readable information, this requirement becomes the last hard nut to crack in closed-loop management of risks. Bugra Karabey proposed introducing NLP into cybersecurity risk management and explored how to identify risk types based on document themes and to identify the patterns and relationships within clustered risk management datasets. His research is of great value to closed-loop management of risks by using the critical information infrastructure governance architecture.