
In actual attack scenarios, when the source code is often unavailable, a white-box-based model is used to analyze software vulnerabilities. Hackers mostly conduct black-box scans against running systems or services, looking for possible vulnerabilities to attack.
DAST simulates a hacker’s attack using an outside-in detection technique on systems or services at runtime to detect possible vulnerabilities and conduct timely remediation.
System Vulnerabilities Scanning
A scan is performed on the given host to collect information about the target host, such as operating system type, host name, open ports, services on the port, running processes, routing table information, open shared information, MAC address, etc. Vulnerability detection is then performed on the host system or service.
The process of system vulnerability scanning can be summarized into four parts:
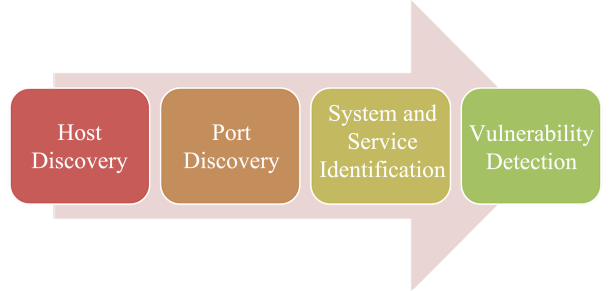
System Vulnerability Scanning Workflow
(1) Host Discovery
When running a system vulnerability scan, the target system is first probed to see if it is alive – powered on and well-connected to the network. Under the default setting, for systems that are not alive, the scan for the target system is automatically skipped, and a new scan for the next target is initiated. Techniques used to detect live hosts include ICMP PING, UDP PING, and TCP PING.
(2) Port Discovery
For live hosts, it is also necessary to detect what ports are open on the host. For Port 1-1024, you can know which default service occupies the port. The TCP connection is mainly used for port detection. It includes complete TCP connection and incomplete TCP connection (TCP SYN).
(3) System and Service Identification
When conducting operating system version identification, the black-box testing method is used based on the different characteristics of each operating system in the implementation of the TCP/IP protocol stack. By studying its response to various probes, an identification fingerprint is formed to identify the operating system running on the target host. The main techniques used include:
Passive identification: The operating system is identified by capturing packets and analyzing the different characteristics of the packets (TCP Window-size, IP TTL, IP TOS, DF bits, and other parameters). It relies on network topology.
Active identification: Identify the operating system by sending specially constructed packets and analyzing the response mode of the target host. For example, if a FIN/PSH/URG packet is sent to a closed TCP port, most operating systems set ACK as the initial sequence number for the received message, while Windows sets ACK as the initial sequence number of the received message plus 1. Based on this feature, the target operating system can be identified as a Windows operating system if the operating system reports ACK as the initial sequence number plus 1.
Identifying the application service version mainly relies on the system Banner information reported by the application system.
In general, Port 1-1024 all correspond to default services. For example, the mail servers correspond to Port 25, web servers correspond to Port 80, and domain name servers correspond to Port 53. However, it is not guaranteed that all ports correspond to the default server developed. For example, servers that provide services to the wide area network need remote management. Therefore, the SSH service is opened. But in order to prevent the SSH service from being directly exposed to the wide area network, the administrator connects SSH to Port 9821. Normally, this is a non-standard port. In this case, the non-standard service identification technique can be used to accurately detect and identify the services provided by this port. The non-standard service identification technique detects the use of standard services on the port. It then matches the information returned by the server with the service identification fingerprint database to determine which service corresponds to the port.
(4) Vulnerability Detection
After completing host survival discovery, port discovery, and system and service identification, there will be a password guessing on the target system based on the information of the system and services identified. If it succeeds, local scanning will be initiated to find out if the target host has vulnerability by comparing and analyzing it with the vulnerability database. Alternatively, by remote scanning, direct online communication with the target system or service is also available. By sending specific packets and receiving feedback from the target system, it can be determined whether there are specific vulnerabilities in the system. System vulnerability scanning is usually done remotely because local scanning requires logging into the target host, which is technically difficult to apply. According to different principles of scanning detection, remote scanning technology can be divided into three categories: version scan, principle scan, and fuzzy scan. Their differences are as follows: Version scan is a kind of remote vulnerability scanning technique. The vulnerability scanning system identifies the version information of the system or service, such as Banner and others. The system then compares the information with the vulnerability database to determine whether the target has vulnerabilities. Version scan has no impact on the target and is highly secure. However, there is a risk of false positives in the version identification process, resulting in false positives of vulnerabilities. The remote scanning process of most products uses this technique.
Principle scan is a kind of remote vulnerability scanning technique. The vulnerability scanning system sends special packages to a target host. It collects information from the target host to determine whether a specific patch is installed on the system and thus determines whether system vulnerability exists. The principle scan has a very low false positive rate, but it is difficult to develop scanning plug-ins, so most products do not have the capability to use this technique.
The fuzzy scan is somewhere between the version scan and the principle scan. It is more accurate by constructing special packages that identify the characteristics of the target host to analyze the existence of vulnerabilities. However, there are only few fuzzy scan plug-ins, and there are also cases of false positives and false negatives. Currently, only a small number of products are capable of using this technique.
Web Vulnerability Scanning
Vulnerability scanning of a running Web program can be divided into three stages in general: page crawling, probe point discovery, and vulnerability detection. The first stage is done by the crawler and the last two stages depend on the results of the first stage. Page crawling and vulnerability detection can be conducted simultaneously, or you can wait for the crawler to finish crawling the site before handing it over to the vulnerability detection engine for processing.
(1) Page Crawling
The focus of page crawling is to get the site tree from the entire site quickly and completely. The process is divided into two steps: network access and link extraction. Network access needs to support setting cookies, customizing request headers, setting proxies (http, https, sock4, sock5), various authentication methods (basic, ntml, digest), and client certificates, etc. After getting the response, automatic identification of the response’s encoding method will begin, and it will be converted to the unified UTF-8 encoding for subsequent operations such as link extraction. Currently, in addition to extracting links from static content such as HTML, HTML annotations, Flash, WSDL, etc., it can also use WebKit to extract static and dynamic links from DOM trees, JS, Ajax, etc.
In addition to using the various crawl settings and intelligent techniques mentioned above, it is also necessary to determine the survival of the site, actively identify page types (such as images, external links, binary files, other purely static files, etc.), and try to guess and mark directories that cannot be parsed from other pages but may exist. The survival determination’s primary goal is to provide a prompt answer regarding whether the site is reachable or not (which may be related to the user’s input, configured proxy, authentication information, and the site itself), hence avoiding needless labor. By identifying the page type, the plug-in can distinguish which pages may have vulnerabilities that need to be scanned and which pages can be directly skipped. Guessing possible links based on a certain dictionary is to discover as many pages as possible. This can facilitate the plug-in to report vulnerabilities in sensitive files based directly on guessed markers.
Logical redundancy can be significantly decreased and the scanning engine’s efficiency can be enhanced by gathering and tagging as much data as feasible during crawling.
(2) Probe Point Discovery
Different plug-ins are targeted to find different probe points in the request. Possible probe points include URL path, GET method, URL parameters, parameters in the body of POST method request, fields in the request header, keys in the cookie, and response body, etc. In general, the plug-in will try to parse the unscanned URL and decompose various detection points for possible vulnerability, and leave them for subsequent vulnerability detection.
(3) Vulnerability Detection
Each specific vulnerability has a corresponding plug-in for detection. The plug-in builds targeted network requests based on the detection points it has collected. Then it uses a remote website vulnerability scanning detection technique to conduct vulnerability detection and assess whether the associated vulnerability exists. In addition to the vulnerability detection techniques, for plug-ins that need to send multiple probing requests, network requests are concurrent, and network responses are processed serially to alleviate performance problems caused by network access and to speed up scanning. Meanwhile, to avoid sending repeated network requests in a short period (some plug-ins do not need to reconstruct the request body and use the same network requests as crawlers), web caching is used to reduce the impact of network access on scanning speed. Also, based on the system load at the time, the engine is able to automatically adjust the number of concurrent processes processing URLs in the scanning process (provided the number of processes configured by the task is not exceeded), thus obtaining an optimal system throughput.
There are two categories of vulnerabilities in vulnerability detection:
- Vulnerability Scanning for URL:
In the case of XSS: Split the target URL and then detect each parameter. To begin with, add a normal string to the original parameter value. It will find out if the input string exists in the content of the response page and then analyze the content. Afterwards, it will re-enter the specific string and determine if the specific string entered can be performed based on the analysis of the contest. If not, or some of the strings entered are filtered, other specific strings will be re-entered for verification.
- Specific Vulnerability Scanning for Open Source CMS
In the case of WordPress: During the crawling, the crawler will identify the site by some characteristics. If it determines that the scanned site uses WordPress, it will call all the vulnerability detection plug-ins related to WordPress. Then these detection plug-ins will locate specific vulnerabilities in WordPress.
DAST technique does not require knowledge or a view of the internal architecture and source code of the software. It can be used to verify the quality of the delivered software or to scan periodically during the operational phase to facilitate the timely detection and patching of vulnerabilities. DAST technique is useful for identifying security issues, but there are also some shortcomings worth noting. Firstly, DAST relies on security experts to create correct test procedures, but it is difficult to create comprehensive tests for each application. It is also likely that DAST technique will create false positive test results, identifying valid elements of the application as threats. Secondly, DAST focuses on requests and responses and cannot accurately identify the location of risk code locations as SAST techniques can. In addition, DAST detection is typically slow. It may take days or weeks to complete the test. Moreover, because it occurs in the late stage of SDLC, the issues found can bring many tasks for the development team and increase the corresponding cost.
Previous posts on software supply chain security:
- Software Supply Chain Security: Overview
- Threats against Software Supply Chain Security
- The Increasing Trend of Software Supply Chain Attacks
- The Increasingly Complex and Varied Vectors to Attack Software Supply Chain
- Security Concept for Software Supply Chain (Part 1) — Transparency of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 2) — Assessable Capabilities of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 3) – Building Trusted Software Supply Chain
- Relationship Between Security Concept and Security Assessment for Software Supply Chain
- Technical Framework of Software Supply Chain Security
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 1)
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 2)
- Key Technologies for Software Supply Chain Security – Detection Techniques (Part 1) – Software Composition Analysis
- Key Technologies for Software Supply Chain Security – Detection Techniques (Part 2) – Static Application Security Testing (SAST)