
NSFOCUS Security Labs is keeping an eye out for the trends in supply chain security and is pleased to share observations and thoughts with our blog readers. You will see the links for more posts we published about software supply chain security at the end of the article.
From the perspective of the software life cycle, the software supply chain can be divided into three major links of development, delivery, and use. Each link may introduce security risks into the supply chain, and security issues in the upstream link will be transmitted to the downstream link. The development link is the upstream link of the software supply chain. It is very necessary to start from this link for early discovery and fix of security issues. As early as 2005, the US President’s Information Technology Advisory Committee in the annual report on information security pointed out that security detection, especially at the software code level, must be strengthened for software products used in the US key departments. Under the joint funding of the US Department of Homeland Security (DHS) and the US National Security Agency (NSA), MITER has carried out research on flaws in the software source code and established CWE (Common Weakness Enumeration), a category system for software source code weaknesses, to uniformly classify and identify flaws in the software source code. Third-party research institutions such as CERT, SANS, and OWASP in the US have also carried out a lot of work in the security detection of the software source code. For example, the CERT organization has developed secure coding standards (such as C/C++ and Java). The released SANS Top 25 Most Dangerous Software Errors and OWASP TOP10 are used to guide developers in secure coding and avoid security flaws in the source code to the extent possible.
SAST is just such a way for security detection of the source code in the development process. With built-in rules for different types of flaw detection, it can convert the source code into an easy-to-scan intermediate data format and conduct analysis through the flaw detection technique. By matching flaw rules, it discovers flaws in the source code and provides remedial suggestions to help users fix them early, thus reducing the cost of later repairs and enhancing software security. The principle of static security analysis is shown in the figure below:
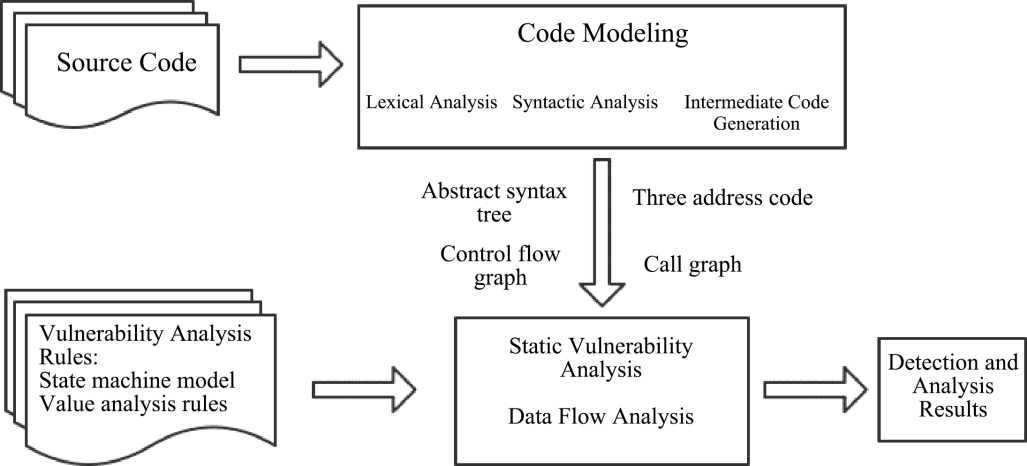
The common types of static vulnerability analysis are as follows:
(1) Syntactic Analysis
Syntactic analysis refers to the process of processing lexical expressions according to the grammatical rules of a specific programming language, analyzing the results generated by the program, and generating a syntax tree. This process can judge whether the structure of the program is consistent with the pre-defined BNF paradigm, that is, whether there are grammatical errors in the program. In general, the BNF paradigm of a program is described in context-free grammar. The main methods that support the syntactic analysis include the operator precedence parser (bottom-up), recursive descent parser (top-down), and LR parser (left-to-right and bottom-up). Syntactic analysis is an important step in compiling and the basis for other analyses.
(2) Type Analysis
Type analysis mainly refers to type inspection. The purpose of type inspection is to analyze whether there are type errors in the program. Type errors usually refer to operations that violate type constraints, such as multiplying two strings and accessing an array out of bounds. Type inspection is usually static, but can also be dynamic. Type inspection at compile time is static. For a programming language, if the types of all its expressions can be determined through static analysis and thereby type errors are removed, then this language is a statically typed language (also a strongly typed language). Programs developed in statically typed languages can remove many errors before running. Hence, it is relatively easy to guarantee the program quality (but weak in the flexibility of expression).
(3) Control Flow Analysis
The output of control flow analysis is a control flow graph, which describes information about the program structure, including conditions and loops. A control flow graph is a directed graph, as shown in the figure below. Each node in the graph corresponds to a basic block, and the edge usually corresponds to the directions of branches.
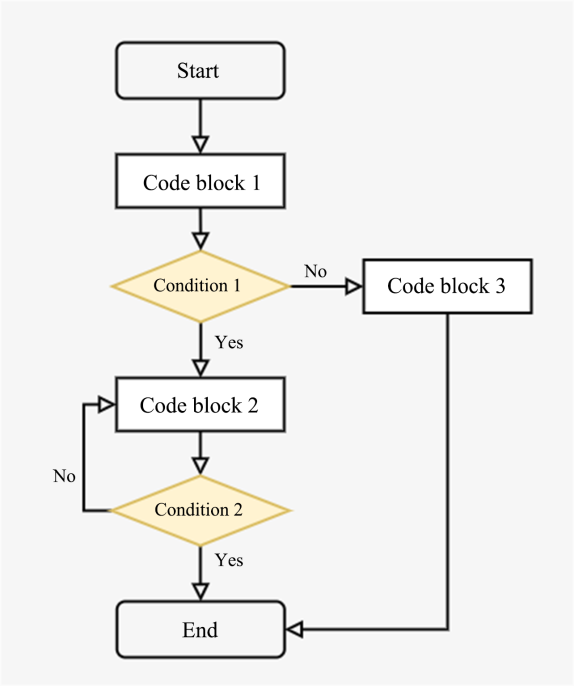
(4) Data Flow Analysis
Data flow analysis is used to obtain information about how data flows along the program execution path. On the control flow graph of the program, it calculates the data flow information before and after each node and through data flow analysis, generates the data flow graph.
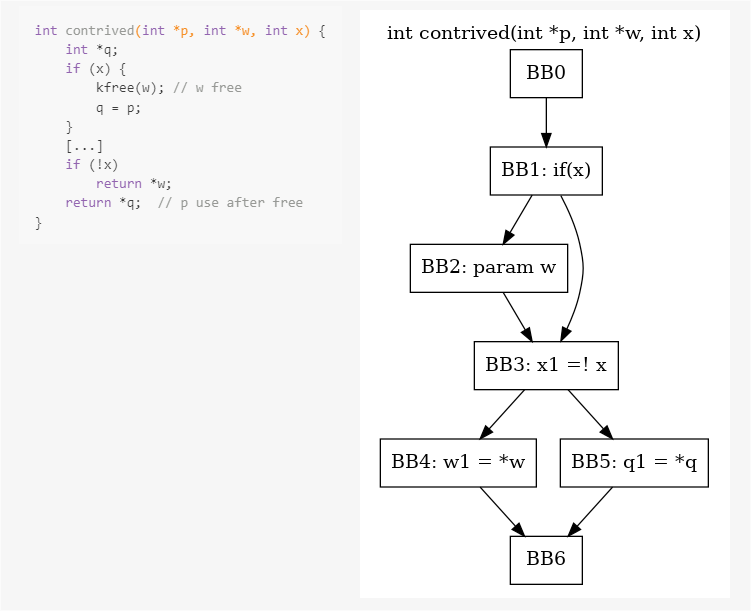
The code example diagram of the data flow analysis is shown above. If the parameter w is data with vulnerabilities, then the data flow path BB0->BB1->BB2->BB3->BB4->BB6 is not secure.
Data flow analysis is widely used in static analysis to analyze variable states (such as unused variables and dead code). At the same time, taint propagation analysis is also an application of data flow analysis. In vulnerability analysis, taint analysis is used to mark the data of interest (usually from the external input of the program) as tainted data. By tracking the flow of information related to tainted data, we can know whether they will affect some key program operations, and then discover program vulnerabilities.
Flaws are generally divided into the following three types:
(1) Input Validation Flaws[1]
Input validation flaws refer to the flaws caused by the program not validly verifying the input data. Common input validation flaws include SQL injection, XML external entity injection, command injection, and XSS (cross site scripting).
For input validation flaws, it is necessary to verify the input. The validation content includes whether the data contains the unexpected character, data range, data length, and data type. If it contains dangerous characters, such as <, >, “, ‘, %, (, ), &, +, \, \’, \”, and ., these dangerous characters also should be escaped. All untrusted output, such as interpreter queries (SQL, XML, and LDAP queries) and operating system commands, can also be sanitized through validation, effectively reducing some security issues.
(2) Resource Management Flaws
Resource management flaws refer to flaws caused by the program’s improper management or use of resources such as memory, files, streams, and passwords. Common resource management flaws include buffer overflow/underflow, unreleased resources, memory leaks, and hard-coded passwords.
For such flaws, when memory allocation is required, the cache size should be inspected to ensure that there is no danger of exceeding the size of the allocated space. Resources such as memory, files, and streams should be properly released after their use.
(3) Code Quality Flaws
Code quality flaws refer to flaws caused by poorly written code. Poor code quality may lead to the occurrence of unpredictable behaviors. Common code quality flaws include integer problems, null pointer dereferences, initialization problems, and improper loop termination.
In response to code quality flaws, it requires targeted solutions. For example, for integer problems, operating results should not go beyond the value range of integers; and when the pointer is used, a judgment on whether it is empty is required. Good programming habits should be developed.
SAST does not need to run programs, covering 100% of the code base, but there may be false negatives or false positives in the inspection results. Generally, it requires continuous optimization of detection techniques and detection rules to reduce false positives and false negatives.
Previous posts on software supply chain security:
- Software Supply Chain Security: Overview
- Threats against Software Supply Chain Security
- The Increasing Trend of Software Supply Chain Attacks
- The Increasingly Complex and Varied Vectors to Attack Software Supply Chain
- Security Concept for Software Supply Chain (Part 1) — Transparency of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 2) — Assessable Capabilities of Software Supply Chain Compositions
- Security Concept for Software Supply Chain (Part 3) – Building Trusted Software Supply Chain
- Relationship Between Security Concept and Security Assessment for Software Supply Chain
- Technical Framework of Software Supply Chain Security
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 1)
- Key Technologies for Software Supply Chain Security—Techniques for Generating and Using the List of Software Compositions (Part 2)
- Key Technologies for Software Supply Chain Security – Detection Techniques (Part 1) – Software Composition Analysis