
At RSA Conference 2019, Tao Zhou, a senior staff algorithm engineer from Alibaba Security, Alibaba Group, as one of only a few Chinese speakers, started his presentation on application of statistical learning to intrusion detection in the context of massive big data with an account of challenges facing Internet giants in security data analysis, and then shared his constructive ideas on this topic.
For starters, Tao Zhou pointed out that in security defense and attack, the biggest advantage defenders have lies in massive data of various types.
However, data is a double-edged sword. How to put massive data into good use is a common question baffling defenders in the era of big data.
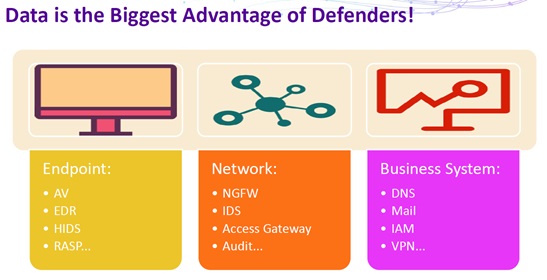
Massive data is far beyond the human capacity to process. Therefore, it is high time for computers to step in, relieving people of the burden of complex computation with various algorithm models, as represented by machine learning and statistical modeling.
Tao Zhou thinks that the most distinctive difference between the two models is that machine learning relies on training data (preferably labeled data), but statistical modeling relies on human’s understanding of data traits.

Machine learning, when applied as the only approach to intrusion detection, would encounter a lot of problems because machine learning is good at detecting “normal patterns”, but intrusion is abnormal behavior. Moreover, for supervised learning, machine learning algorithms need large amounts of labeled data, which are hard to obtain. For unsupervised learning, currently the accuracy and recall rate of almost all related algorithms cannot support security operations. Finally, the biggest problem of machine learning is that the classification model built on data training is usually too complex to interpret. The simple answer of “Yes” or “No” is insufficient for security analysis.
Therefore, when applying machine learning to intrusion detection, we usually need to specify certain scenarios, typically those where labeled data is easy to obtain, like spam detection, DGA domain detection, and web crawler detection.

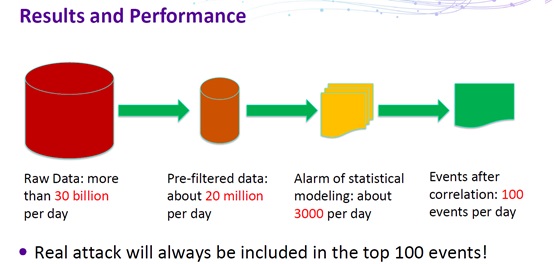
Tao Zhou then went further to illustrate the common process of applying statistical modeling to intrusion data analysis. First, he pointed out that, effective attacks always take a long process, generally spanning a long time period with multiple stages and originated from multiple nodes.

Security data analysis consists of three steps:
- Data preprocessing
Remove interference of normal data.
- Attack modeling
Build an attack model that can identify suspicious behavior.
- Alarm correlation
Prioritize alarms based on the risk level.
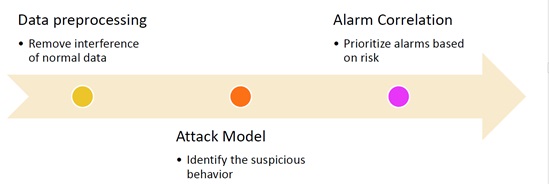
During data preprocessing, data of the most frequently repeated behavior, which is always normal, should be filtered out. In this step, the recall rate is the most important indicator as it reflects the capability of discerning normal data and the aim of removing as much normal data as possible.

During attack modeling, a model should be built on preprocessed data to reflect a specific type of attack. The same type of attacks tends to have common features, which can be obtained from data of abnormal behavior. In this step, precision is the most important indicator, reflecting an emphasis on the accuracy of determination of attack patterns.

The kill chain-based model is a good option for modeling in this step.
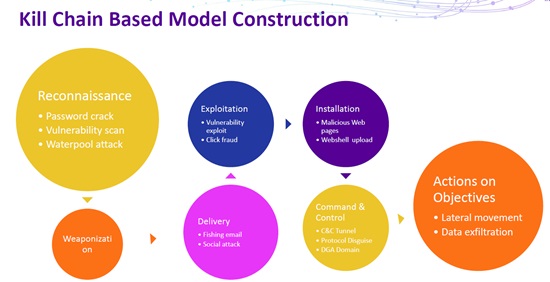
Despite being superior to machine learning that is applied as the only approach to intrusion detection, statistical modeling has its own deficiency as it follows an important principle called “Occam’s razor”, which, simply put, means that parameters should be as few as possible in a model. This causes the model to be less generalized. Besides, in certain scenarios, this may also add to the interference to intrusion detection, as illustrated by Tao Zhu in the following figure.

To make up for this deficiency, Tao Zhu proposed an optimization method. Specifically, build a directed graph of attacks for post-incident risk assessment. Then prioritize incidents according to their risk level and confidence level. The risk is quantified based on such factors as the attack phase, network distribution of assets, and the risk and accuracy of alarms.
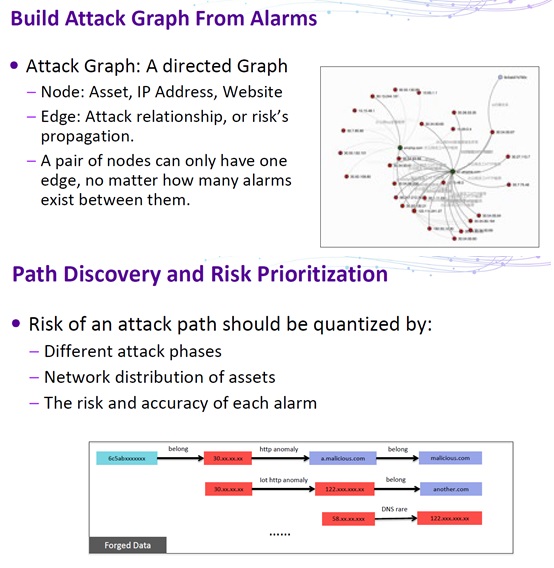
After the preceding three steps are complete, alarm data is cut down to a maintainable scale, making it possible to conduct effective and efficient security analysis in the context of big data.
Sum-up
In intrusion data analysis, it is a must to interpret analysis results. Traditional machine learning algorithms built upon training data, however, are usually “black boxes” that deny interpretation. For this reason, many scholars begin to study the explainable AI (XAI, or interpretable AI), with a purpose of delivering interpretable analysis results, whether using the statistical modeling (for example, topic modeling frequently mentioned at this year’s RSA conference) or the knowledge graph (semantic network) technology (such as Watson from IBM). Nowadays, AI technologies, including machine learning, have been widely applied in numerous scenarios in the security domain. How to continuously optimize solutions and resolve security risks and issues arising during the actual application of such solutions will be a long-term research project.
The threat modeling research team at NSFOCUS is now working on construction of a threat knowledge graph that contains dozens of threat-related databases covering threat actors, attack patterns, attack targets, and the like by using ontology modeling and referring to the international frameworks or standards such as CAPEC and STIX. The knowledge graph keeps expanding based on knowledge obtained from various structured and unstructured data sources to provide context for better understanding of security threat events. It visualizes in more detail security scenarios and supports reasoning based on threat knowledge as well as providing applications such as attack group clustering and profiling.