
As machine learning is increasingly used in data analysis in cybersecurity, there is a risk of privacy disclosure to some extent if models inadvertently capture sensitive information from training data. Since training data will exist in the model parameters for a long time, it is possible to directly output training samples if some data with induced properties are input into the model [1]. At the same time, when sensitive data accidentally enters model training, from the perspective of data protection, how to make the model forget these sensitive data or characteristics and ensure the effect of the model has become an urgent problem to be solved.
Researchers from NSFOCUS Security Labs recommend a method to realize data unlearning through closed-form updates of model parameters, which was derived from a paper presented at the 2023 Network and Distributed System Security (NDSS) Symposium [2] to achieve significant feature and tag data unlearning regardless of whether the loss function of the model is convex or not.
Common Data Unlearning Methods for Machine Learning Models
Commonly used data unlearning for machine learning include the following methods:
Retraining after deleting data, which requires retaining original data and is expensive to retrain. When the data to be modified does not exist independently or there is a large amount of data that needs to be desensitized, it is also difficult to retrain the model by deleting the data.
Another study has addressed the need to reduce privacy disclosure by partially reversing the learning process of machine learning [3] and deleting learned data points during this process. However, the computational efficiency of this method is usually low and has a certain impact on the accuracy of the model, so it is less feasible in actual operation.
The researchers also proposed a fragmentation method to train sub-models based on each partition and aggregate them into the final model by segmenting the data into independent partitions. In this method, data unlearning can be achieved by retraining only affected submodels while remaining unchanged. The disadvantage of this approach is that the efficiency of retraining decreases rapidly when multiple data points need to be changed, and the probability that all submodels need to be retrained increases significantly as the number of data points that need to be deleted increases. For example, when the number of fragments is 20, removing 150 data points requires updating all fragments, i.e., as the number of affected data points increases, the operational efficiency advantage of the fragmentation method over retraining fades away. In addition, removing the entire data point degrades the performance of the retraining model relative to removing affected features and labels.
Machine Unlearning of Features and Labels
To solve this problem, the method presented in this paper transforms the removal of data points into closed-form updates of model parameters from the perspective of solving the privacy problem in features and labels, thus realizing the correction of features and labels at arbitrary positions in training data, as shown in Figure 1.

This approach is more effective than deleting data points when privacy concerns involve multiple data points, but are limited to specific features and labels. In addition, the method has high flexibility and can be used not only to modify features and labels but also to delete data points instead of existing methods.
This method updates the model parameters based on an influence function, which is widely used to measure the degree of impact of samples on model parameters, that is, describe the importance of samples. The influence function can be used to obtain a measure of similarity with the original model without changing the model.

Commonly used modifications to data points or features include data point modification, feature modification and feature deletion. Among them, the deletion of features will change the dimensions of model inputs. Since for a large class of machine learning models, setting the value of the feature to be deleted to zero and training again is equivalent to the training result of deleting the feature, this method chooses to delete the feature instead of setting its value to zero. This method realizes two update modes: first-order updates and second-order gradient updates. The idea is to find updates that can be superimposed on the new model for data unlearning. The first approach is based on a gradient of the loss function and can therefore be applied to any model in which losses are derivative, where Ï„ is the unlearning rate.
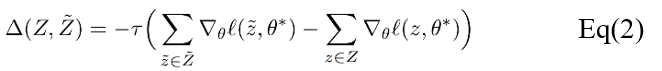
The second approach contains the second-order derivatives, thus limiting its application to loss functions with invertible Hessian matrices. It is technically straightforward to apply second-order updates in common machine learning models, but the inverse Hessian are often difficult to compute for large models.

For models with a small number of parameters, the inverse Hessian matrix can be computed and stored in advance, and each subsequent data unlearning operation involves only simple matrix vector multiplication, so that computational efficiency is very high. In tests, for example, it has been shown that removing features from a linear model having approximately 2000 parameters can be realized in less than a second. For complex learning models such as deep neural networks, the approximate inverse Hessian matrix can be used instead because it is large and difficult to store. In the test results, a recurrent neural network with 3.3 million parameters was calculated second-order updates in less than 30 seconds.
Example Demonstration
For the tested examples, this task analyzes the performance effectiveness of the proposed method depending on three properties: An effective method must (1) remove the selected data, (2) preserve the model’s quality, and (3) be efficient compared to retraining. To compare this method with the existing data unlearning methods of machine learning models, retraining and fragmentation are selected as baselines in this task.
Unlearning of Sensitive Features
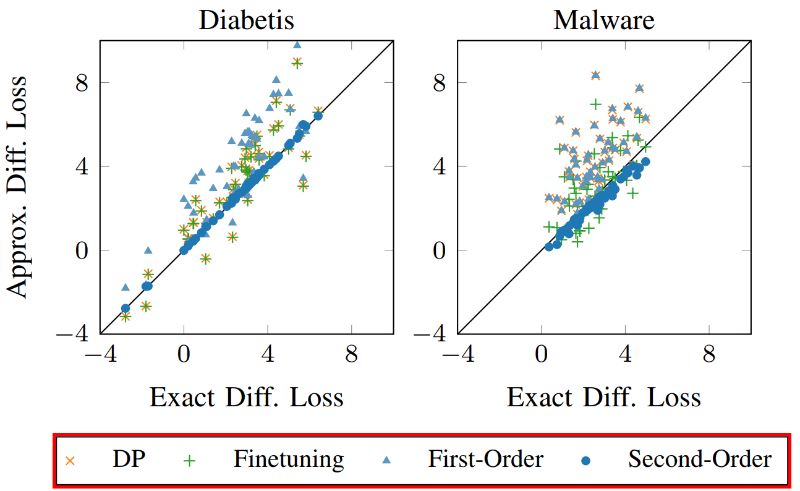
This method is first applied to logistic regression models trained on real datasets, including spam filtering, Android malware detection, diabetes prediction, etc. For datasets with many feature dimensions, such as email and Android application datasets, this method selects the dimensions related to personal names and URLs extracted from Android applications as sensitive features respectively, and removes the entire feature dimension from the model. For datasets with fewer feature dimensions, the method chooses to replace selected feature values. For example, for diabetes datasets, individual feature values such as age, body mass index and gender can be adjusted instead of being deleted directly. Figure 2 shows the effect of removing or replacing 100 features from the diabetes and malware datasets, respectively. We observed that the second-order update is very close to retraining because these points are near diagonals. In contrast, other methods do not always adapt to changes in the distribution, leading to greater variability.
Unlearning of Unintended Memorization
Previous studies have shown that some language learning models can memorize rare inputs in training data and accurately display these input data in the application process [4]. If such unintended memories contain privacy data, there are risks of privacy leakage. Because the loss of the language model is a non-convex, it cannot theoretically verify the effect of data unlearning. In addition, A simple comparison to a retrained model is also difficult since the optimization procedure is nondeterministic and might get stuck in local minima. Based on these limitations, exposure metric is used to assess the effects of data unlearning.
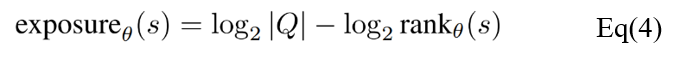
where s is a sequence and Q is the set of possible sequences with the same length given a fixed alphabet. The exposure measure is able to describe the likelihood of a sequence s with respect to all possible sequences of the same length generated by the model. As shown in the Table below, for all sequence lengths, the exposure values of the first-order and second-order updates are close to zero, i.e. it is not possible to extract sensitive sequences.

Conclusion
By applying this data unlearning method in different scenarios, it is proved that the strategy has high efficiency and accuracy. For logistic regression and support vector machines where the loss function is convex, it can be theoretically guaranteed to remove features and labels from the model. Compared with other data unlearning methods, this method has higher efficiency and similar accuracy after being verified in practice. It only needs a small part of training data and is suitable for situations where the original data are unavailable.
At the same time, the efficiency of the data unlearning method in this task decreases with the increase of affected features and labels. Currently, it can effectively deal with the privacy issues of hundreds of sensitive features and thousands of labels, but it is difficult to implement on millions of data points. In addition, for models with non-convex loss functions such as deep learning neural networks, this method cannot theoretically guarantee that the data unlearning function can be implemented in the model without convex loss functions, but the efficacy of data unlearning can be measured in other ways. When applied to a generative language model, it can eliminate unintended memories while preserving the functions of the model, thus avoiding sensitive data leakage.
References
[1] X. Ling et al., Extracting Training Data from Large Language Models, in USENIX Security Symposium, 2021.
[2] Alexander Warnecke et al., “Machine Unlearning of Features and Labels”, in NDSS 2023.
[3] L.Bourtoule et al., “Machine unlearning”, in IEEE Symposium on Security and Privacy (S&P), 2021.
[4] N. Carlini et al., “The secret sharer: Evaluating and testing unintended memorization in neural networks,” in USENIX Security Symposium, 2019, pp. 267–284