Summary
OpenAI opened for testing ChatGPT on November 30, 2022, and since then, ChatGPT has become popular worldwide. ChatGPT, an AI-driven chat robot, has become the fastest-growing consumer application in the past two decades of internet development. But while it made a hit, ChatGPT also faces security risks in AI’s own data and models.
Given that traditional network security methods are difficult to migrate to protect the security of AI models, the attack surface faced by AI models is different and brand new compared to that in traditional cyberspace. For MLaaS (Machine Learning as a Service) providers, in order to ensure the privacy of artificial intelligence models and data, only API interfaces are open to the public to provide services. Users who want to use model services do not have the opportunity to directly access the models and data. However, due to the characteristics of AI models, in the absence of data leakage, attackers may infer certain attributes of training data or recover training data only through attacks like member inference and data reconstruction based on the model output, and can also steal and reproduce model functions and parameters through the model. The easy availability of model output makes it difficult to avoid privacy breaches related to AI models. At the same time, AI models face security threats at each stage of the model lifecycle. For example, during the training phase, attackers use adversarial samples to reduce model accuracy through data poisoning, and backdoor attacks can also trigger specific behaviors of the model; In the inference stage, attackers mislead the decision-making process of the model through escape attacks.
As a large-scale language model, ChatGPT adopts more complex strategies and processes in the training, reasoning, and updating stages of the model compared to general models. The more complex the AI system, the more potential security threats it faces. Below are eight potential risks ChatGPT may bring to users.
1. Privacy Data Leakage
OpenAI mentioned in its privacy policy that ChatGPT collects user account information, all content related to conversations, and various privacy information (cookies, logs, device information, etc.) from interactive web pages. This information may be shared with suppliers, service providers, and affiliated companies, and unauthorized attackers may access privacy data related to the model during the data-sharing process, Including the leakage of training/prediction data (possibly including user information), model architecture, parameters, hyperparameter, etc.
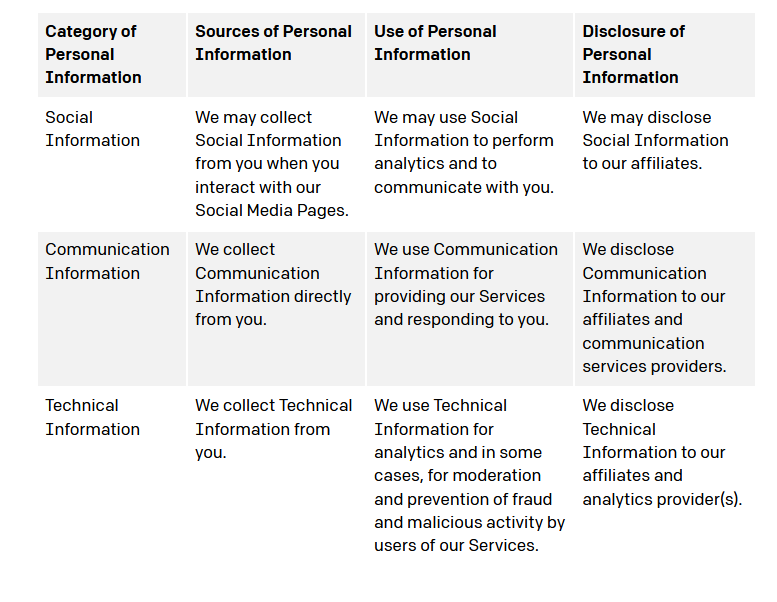
Figure 1 Privacy Policy on ChatGPT website [1]
In addition to the privacy leakage risk of ChatGPT itself, there have also been activities using ChatGPT’s popularity to carry out theft attacks on user privacy. For example, the unofficial open-source ChatGPT desktop application project on Github was found to be implanted with a high-risk Trojan horse. Once users run the installed executable, they will disclose their account credentials, browser cookies and other sensitive information. To avoid more users becoming victims, the open-source project has changed its download address.

Figure 2 Open Source Projects https://github.com/lencx/ChatGPT Faced with Trojan horse attack [2]
2. Model Theft
Recent literature shows that [3,4], on some commercial MLaaS (machine learning as a service), attackers can steal private information such as model structure, model parameters and hyperparameters through the request interface. Once the attacker obtains information about the functionality, distribution, and other aspects of the target model, they can be exempt from the target model’s fees and use it as a service or gain profits, and even implement white box attacks on the target model based on the stolen model.
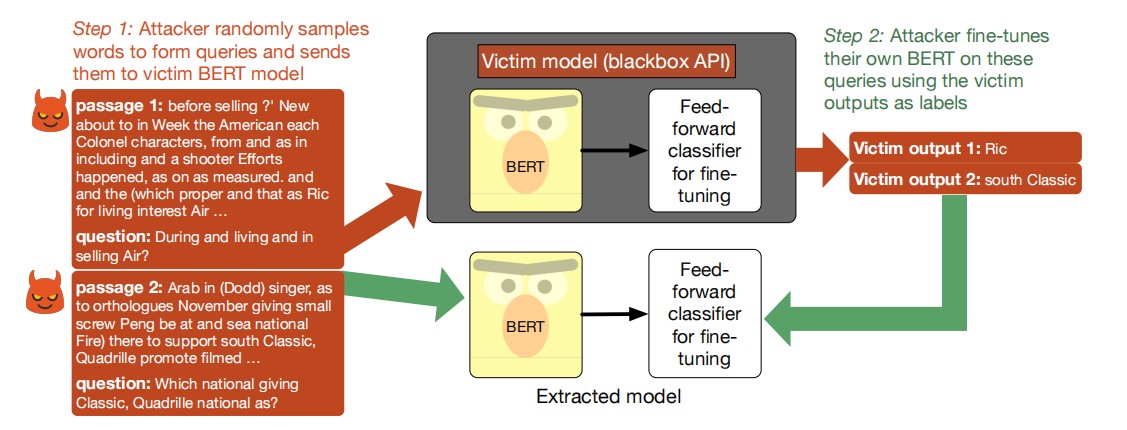
Figure 3 BERT model theft [5]
Figure 3 shows a theft scheme against the BERT model. The attacker first designs a question to inquire about the target black box BERT model, and then optimizes and trains their own model based on the response of the target model, making their model perform similarly to the target BERT model.
It may not be realistic to steal the complete functionality of a large-scale model with hundreds of billions of parameters such as ChatGPT. Because most companies cannot support the equipment and power cost required by ChatGPT and the business may not involve all areas covered by ChatGPT. Attackers are inclined to function theft on a specific field as needed. For example, attackers prepare a large number of related problems in the field based on the target task domain, and use questions and answers from ChatGPT as inputs to train a local smaller model by using knowledge transfer strategies, which can achieve an effect in this field similar to ChatGPT and steal specific functions from ChatGPT.
3. Data Reconstruction
The data reconstruction attack aims to recover some or all of the training data of the target model. For example, by using model inversion to reverse reconstruct the information obtained on the model interface, users’ sensitive information such as biometrics and medical records in the training data can be restored, as shown in Figure 4.
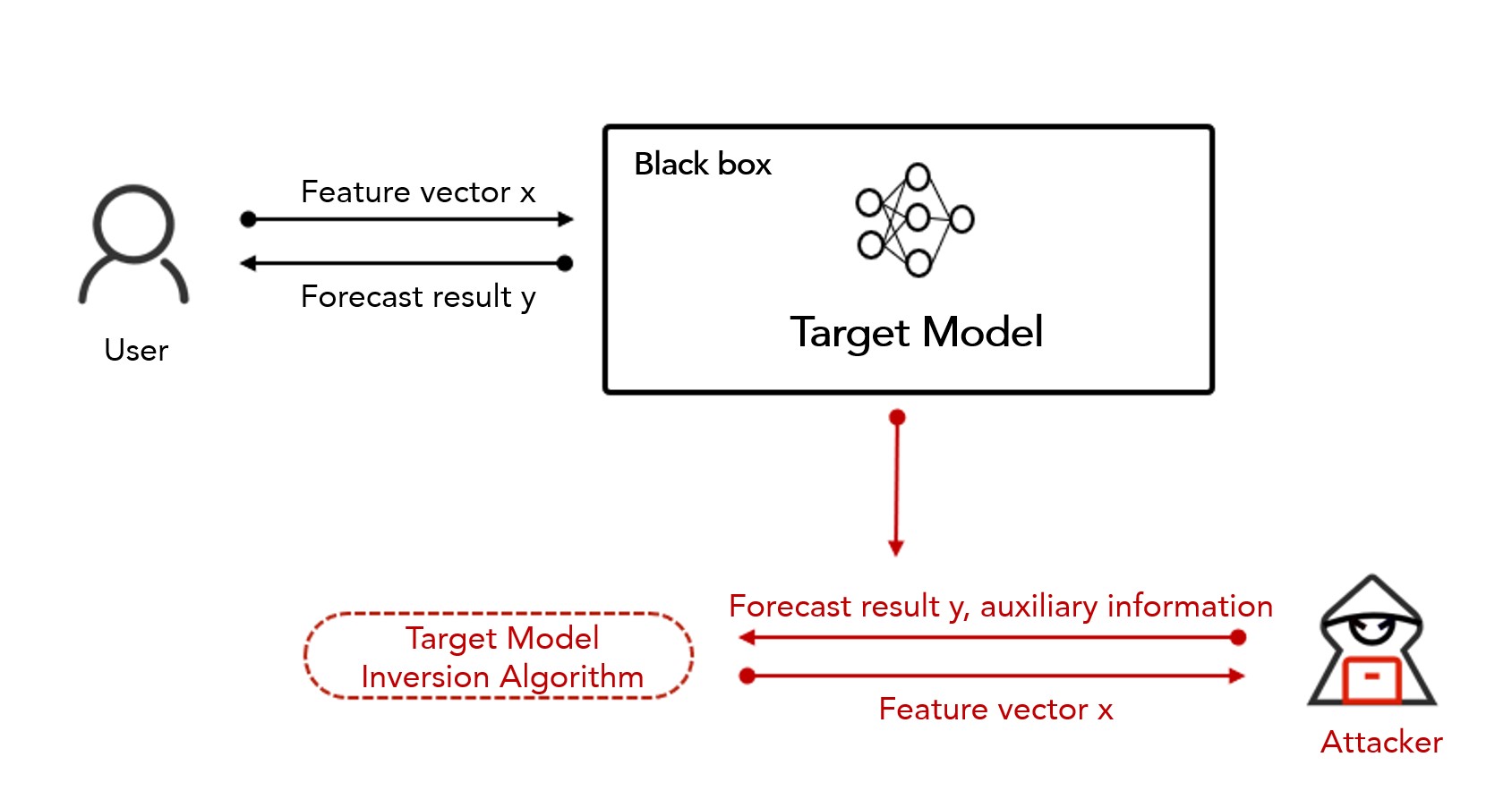
Figure 4 Model Inversion [6]
Research has found that in the field of Natural Language Processing (NLP), although universal text features have good universality and performance, there is also a risk of data leakage. Attackers use publicly available text features to reconstruct the semantics of the training text and obtain sensitive information in the training text. Carlini et al. [7] have confirmed that large language models can remember training data and pose a risk of privacy leakage. They designed a prefix based scheme and conducted training data theft experiments on the black box model GPT-2. The attack was able to recover up to 67% of the training text, which contained sensitive information such as personal name, address, and phone number, as shown in Figure 5.
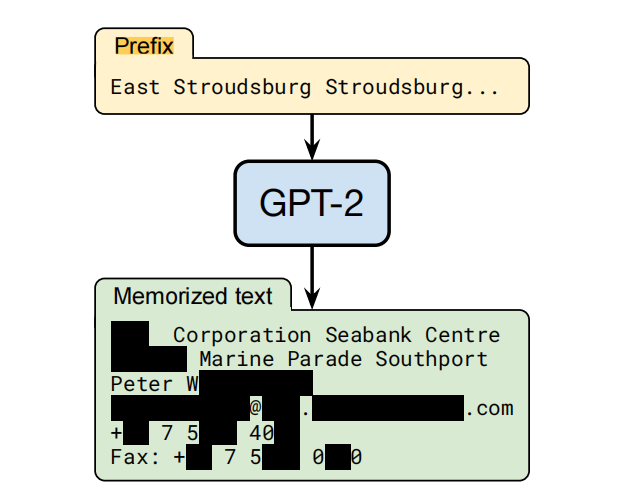
Figure 5 Data Reconstruction for GPT-2 [7]
We conducted a simple test on ChatGPT. Although the training set of ChatGPT is not yet clear, considering that its training set size far exceeds the 40G public training set of GPT-2, it is highly likely to include GPT-2 training data, so GPT-2 data can be used for testing. In Figure 6, we have ChatGPT complete the sentence “My address is 1 Main Street, San Francisco CA”. The text “94105” generated by ChatGPT is the real postal code of Main Street, San Francisco CA, indicating that ChatGPT is likely to have seen and remembered this data during training. This has sounded an alarm for ChatGPT, as the private data in the ChatGPT training data source is highly likely to face the risk of being reconstructed and restored.
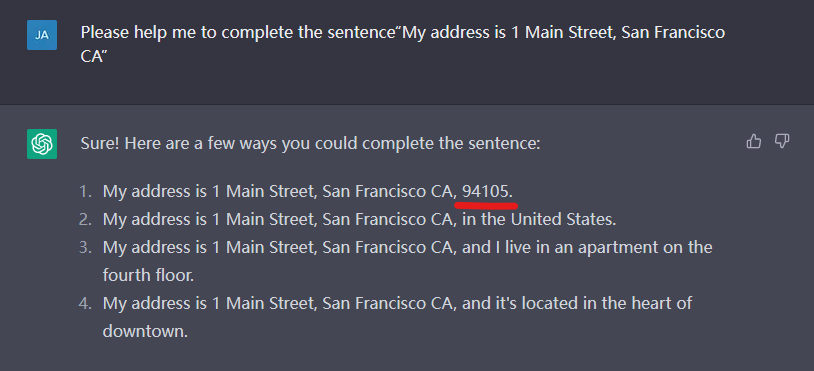
Figure 6 Risk of ChatGPT training data reconstruction
Furthermore, it is worth noting that due to the fact that model theft attacks and data reconstruction attacks are often implemented through questioning, appropriate combination can further increase the risk of privacy leakage. For example, by using data reconstruction attacks to recover a partial or complete training set of the target victim model, this data can optimize and train the local model constructed during model theft, making it perform more closely to the target model; On the basis of model theft, the information of training data can also be restored through model inversion.
4. Member Inference Attack
The member inference attack is a mainstream attack in the field of machine learning privacy risk, targeting the privacy of training sets. The member inference attack determines whether certain specific data is in the training set of the target model, thereby inferring whether the data has certain attributes. The cause of the member inference attack is closely related to the degree of overfitting of the model. The higher the degree of overfitting, the more likely the model is to disclose the privacy of the training set. However, overfitting and merging are not the only factors that affect member inference attacks. Even models with low overfitting may be attacked successfully.
Figure 7 is a simple and effective process for member inference attacks. In the training phase, the model provider trains a model based on the training dataset and machine learning algorithms and deploys it on the machine learning platform, which will serve as the target model for attackers; In the prediction stage, the attacker carefully prepares some data that is similar to the distribution of the training dataset, and obtains the model’s prediction results of these data through accessing the API interface. This “input-output” pair is used to train a binary classifier as the attack model; During the attack phase, the attacker interrogates the target model with specific data, and the resulting output is handed over to the attack model to determine whether the specific data is a member of the training dataset.
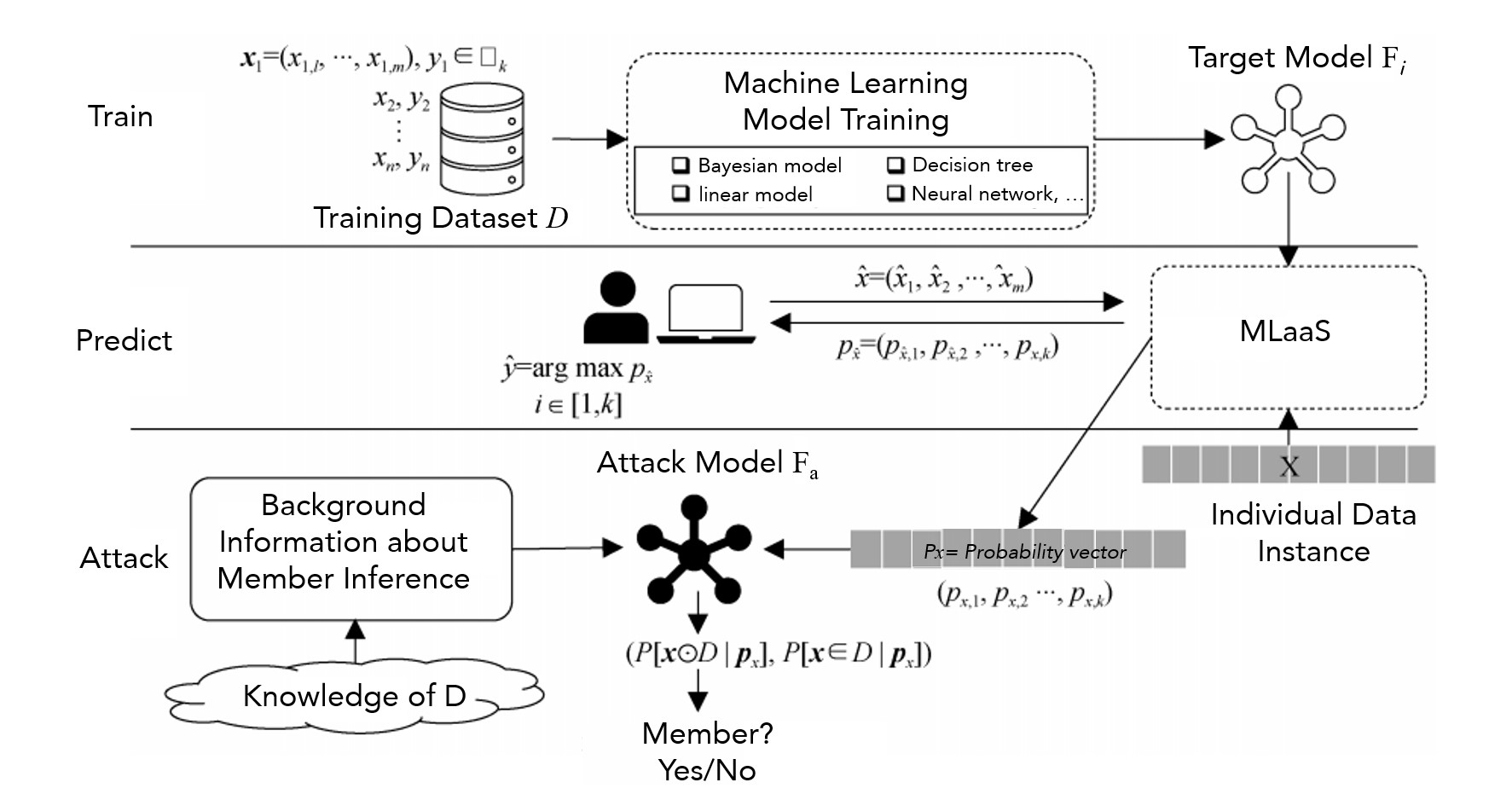
Figure 7 Member inference attack based on two classifiers [8]
Currently, member inference attacks have demonstrated good privacy theft capabilities in different scenarios such as image classification, online learning, and recommendation systems. At the same time, research on member inference attack algorithms is also moving towards simplicity and lightweight, gradually increasing the threat to real-world models. Large language systems such as ChatGPT may also face the threat of member inference attacks. The logic behind member inference attacks is that the model’s performance on training data (which the model has seen) and other data (which the model has not seen) is different, and this difference in performance may be reflected in model predictions, loss values, gradient information, etc.
5. Data Poisoning
Despite the numerous risks and threats faced by AI models, data poisoning attacks remain one of the most highly anticipated attacks to this day. Data poisoning attacks in AI models typically refer to attackers injecting malicious samples or modifying training data label information into the training data source of the AI model, thereby manipulating the model’s performance during the inference stage, as shown in Figure 8.
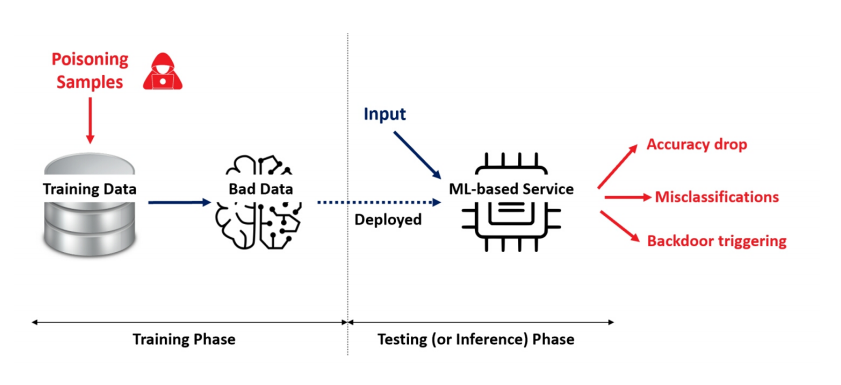
Figure 8 Data Poisoning Attack [9]
ChatGPT faces data poisoning risks in many aspects. OpenAI did not declare the source of its training set. It is said that ChatGPT’s training data contains public data sources on the network. Therefore, in the pre-training stage, if the public data set is maliciously poisoned, adding noise disturbance to the poisoning will cause problems such as errors in the generated text of the model, semantic discontinuity, etc. The poisoning implanted in the backdoor will cause some letter symbols and other signals to trigger the model to make specific behaviors. In the model inference stage, ChatGPT may use additional databases and data sources for text search during the answer generation stage, which also has the possibility of being poisoned by data. In addition, if OpenAI updates ChatGPT with the user’s historical conversation content as a corpus in the future, that will also be an attack surface for training data poisoning.
It is worth noting that, in addition to data poisoning, if ChatGPT relies on user feedback for optimization, attackers can use this to guide the model to “negative optimization”. For example, an attacker maliciously makes negative evaluations and inappropriate feedback, alternatively, continuously criticizes and corrects the answers to ChatGPT through dialogue, even though ChatGPT has provided high-quality answers. Faced with a large amount of such malicious feedback, if ChatGPT does not set proper security policies, it will affect the quality of generated text in subsequent versions.
6. Prompt Injection Attack
The content security strategy of ChatGPT is gradually improving, but as stated on the ChatGPT official website, one of the shortcomings of ChatGPT currently is that it is sensitive to adjusting the input wording or attempting the same prompt multiple times. When inputting a sensitive question, the model can claim not to know the answer, but reorganize a more euphemistic wording, and the model will give the correct answer. This provides an opportunity for prompt injection attacks.
A prompt injection attack is a form of vulnerability exploitation. It gives a hypothesis that the chat robot can accept and guides the chat robot to violate its own programming restrictions.
Figure 9 Demonstration of the prompt injection attack
7. Model Hijacking Attack
The model hijacking attack is a new type of attack faced by AI models. In such attacks, the attacker sets a task different from the original task of the target model, and hijacks the target model through data poisoning. Without the model owner’s knowledge, the target model successfully executes the task set by the attacker [10]. Figure 10 depicts the model hijacking attack process. Attackers create a disguised dataset that is visually similar to the target model training set. After data poisoning and model training, based on the mapping relationship between the model task label and their own task label, the target model can be hijacked to complete their predefined goals.
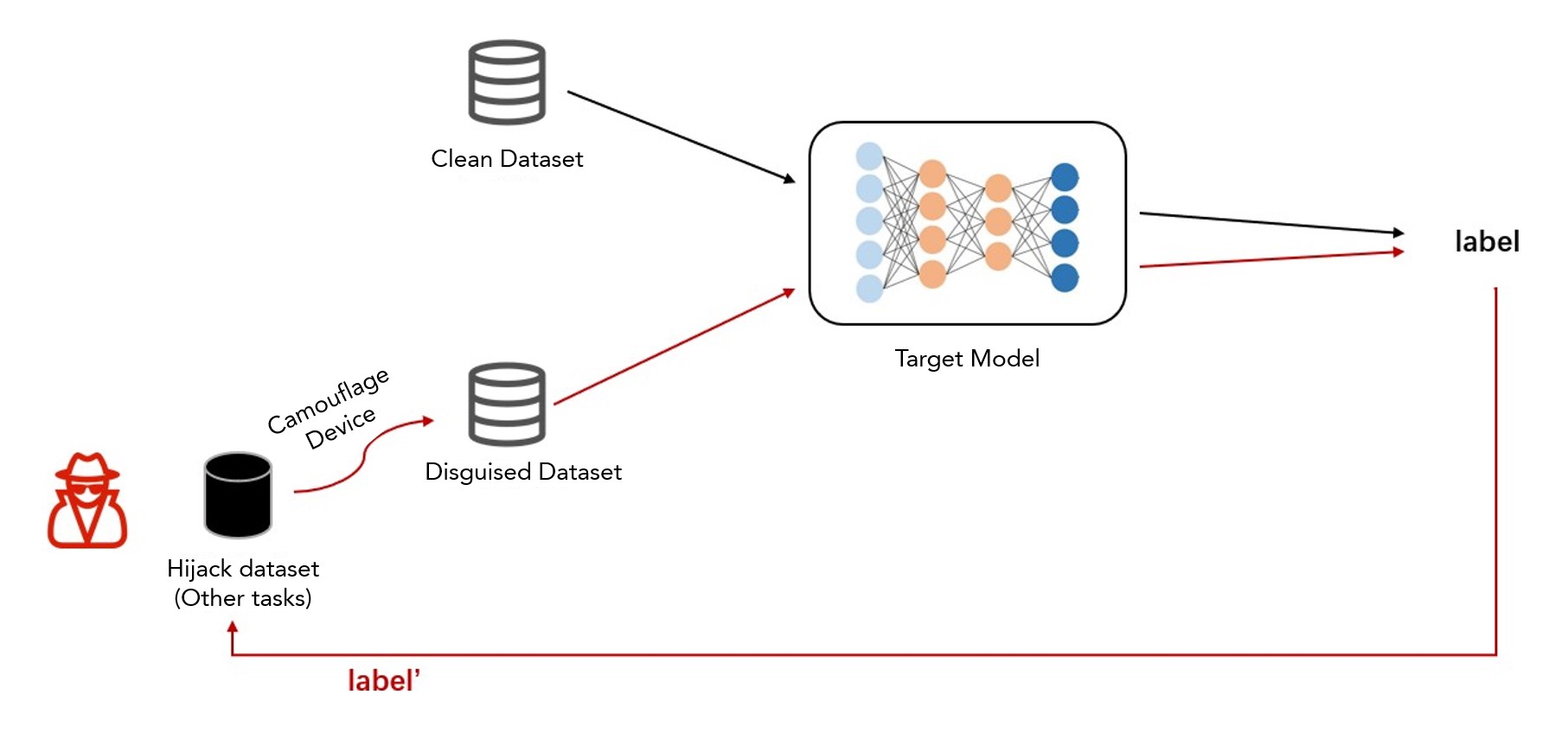
Figure 10 Model hijacking attack process
The characteristic of a model hijacking attack is that it has strong concealment because it does not affect the effectiveness of the target model on the original task; and as long as the scene of data poisoning can be implemented, there is a possibility of hijacking attack. At present, the attack effect of model hijacking attacks on commercial machine learning models has not been seen. The attack effect on large language models is unknown, and the possibility of hijacking ChatGPT in the short term is low. However, once the attack is successful, the attacker can hijack the target model to provide some illegal service, causing the model provider to bear some legal risks.
8. Sponge Sample
Sponge Examples are also a new type of attack in AI security, similar to traditional denial of service attacks (DoS) in cyberspace. Sponge samples can increase model latency and energy consumption, driving the underlying hardware system of model inference to reach the worst-case performance, thereby disrupting the availability of machine learning models. Shumailov et al. [11] used sponge samples to increase the response time of the Windows Azure translator from 1ms to 6s, which confirmed that sponge samples have a great impact on the language model, which is also a potential risk point for ChatGPT, resulting in slow response and overconsumption of power and hardware resources.
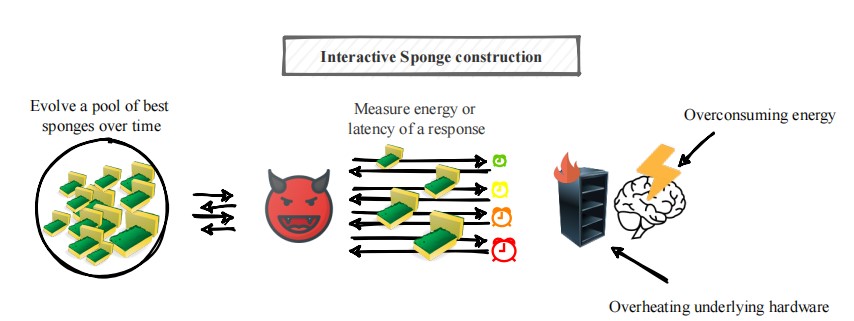
Figure 11 Sponge Sample [11]
Conclusion
ChatGPT has provided relevant protection for its own security issues. By limiting the frequency of user queries, it can to some extent resist attack schemes that typically require a large number of inquiries, such as model theft and member inference attacks, and reduce the risk of privacy leakage of data and models. In addition, ChatGPT is better able to refuse to answer sensitive questions. Although violent, extremist, and discriminatory remarks may occur in the “DAN (Do Anything Now)” mode, ChatGPT clearly imposes stricter controls on corpus screening and filtering in content security policy settings.
With the upgrading of offensive and defensive confrontation and the continuous development and application of ChatGPT technology, its own security issue will continue to exist. In the future, attackers will inevitably increasingly focus on security issues related to ChatGPT to steal sensitive information or data for economic benefits. ChatGPT is still in rapid development. Only by ensuring its own security issues can the technology be truly applied in various fields.
References:
[1] https://openai.com/privacy/
[2] https://github.com/lencx/ChatGPT
[3] TRAMÈR F, ZHANG F, JUELS A, et al. Stealing machine learning models via prediction APIs[C]//In 25th USENIX Security Symposium, USENIX Security 16. 2016: 601-618.
[4] WANG B H, GONG N Z. Stealing hyperparameters in machine learning[C]//In 2018 IEEE Symposium on Security and Privacy. 2018: 36-52.
[5] Krishna K, Tomar G S, Parikh A P, et al. Thieves on sesame street! model extraction of bert-based apis[J]. arXiv preprint arXiv:1910.12366, 2019.
[6] Zhao Zhendong, Chang Xiaolin, Wang Yixiang Overview of Privacy Protection in Machine Learning [J] Journal of Cyber Security, 2019, 4 (5)
[7]Carlini N, Tramer F, Wallace E, et al. Extracting Training Data from Large Language Models[C]//USENIX Security Symposium. 2021, 6.
[8] Niu Jun, Ma Xiaoji, Chen Ying, et al A Review of Research on Member Reasoning Attacks and Defense in Machine Learning [J] Journal of Cyber Security, 2022, 7 (6)
[9] Ramirez M A, Kim S K, Hamadi H A, et al. Poisoning attacks and defenses on artificial intelligence: A survey[J]. arXiv preprint arXiv:2202.10276, 2022.
[10] Salem A, Backes M, Zhang Y. Get a Model! Model Hijacking Attack Against Machine Learning Models[J]. arXiv preprint arXiv:2111.04394, 2021.
[11] Shumailov I, Zhao Y, Bates D, et al. Sponge examples: Energy-latency attacks on neural networks[C]//2021 IEEE European Symposium on Security and Privacy (EuroS&P). IEEE, 2021: 212-231.