
At the 2023 RSA conference, CISO and researchers from Virginia’s Department of Behavioral Health and Developmental Services shared a topic entitled ” Rise of the Machines: Achieving Data Security and Analytics with AI”. They proposed the use of artificial intelligence to rapidly synthesize “de-identified” data, thus avoiding significant resource consumption and human error. In this article, we will interpret this topic and the related technical rationale involved.
I. Artificial Intelligence and Synthetic Datasets
Statistical Learning, Machine Learning, Symbolic Learning, Neural Network… Up to now, AI has formed a huge branch. There are different technologies in each branch. By leveraging these technologies, we are making machines smarter. They can help us with classification and prediction tasks, object recognition tasks, motion capture tasks, and speech recognition and transcription tasks, as shown in Figure 1. To train these machines, however, we need a lot of data to support it. Therefore, a good model usually requires large amounts of training data.

This raises the question of how to obtain such a large amount of data. This question also raises a series of related questions: How to legally collect de-identified and desensitized data under the requirements of private information protection laws? How do we ensure that data can still be effectively used for training after identification and desensitization?
At the conference, Glenn Schmitz presented an approach to using synthetic data—using artificial intelligence to automatically synthesize data, skipping traditional data collection processes and using AI-synthesized data for training or data analysis in other artificial intelligence. As shown in Figure 2, through the CycleGAN technology, we can convert real images into virtual images, such as winter scenes into summer scenes. Glenn Schmitz presented three different approaches at the conference: synthetic minority oversampling techniques (SMOTE), variational auto-encoders (VAEs) and generative adversarial networks (GAN).

II. SMOTE & VAEs & GAN
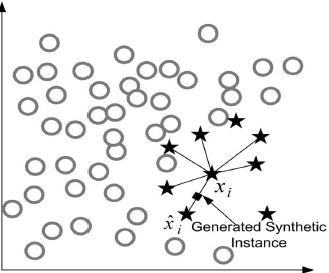
SMOTE is a method of data synthesis with real data. This method uses existing real data sets as the basis and generates new data sets by processing and transforming them. Typically, this involves operations such as sampling, converting, enhancing or adding noise to the raw data to generate more samples. The main advantage of using real data for data synthesis is that the generated data can reflect the true characteristics and distribution of the original data set. Specifically, SMOTE increases the number of minority samples by interpolating between them to generate composite samples. As shown in Figure 3, the SMOTE method selects a few class samples and their nearest samples, and then randomly interpolates between them to generate new samples. This can increase the number of minority class samples, balance data sets, and improve the classification performance of machine learning algorithms for minority classes.
In contrast, VAEs and GAN are both methods of data synthesis without real data. This approach does not rely on any real dataset (the generated data is independent of the real dataset and may be required for model training) but uses a variety of modeling techniques to generate synthetic data. By learning the characteristics and distribution of the original dataset, these models can generate synthetic data similar to the original data. The advantage of not using real data for data synthesis is that a large number of data samples can be generated, enabling model training and algorithm evaluation even when raw data are scarce or difficult to obtain. However, since the data generated is not based on real-world observations, complexity and uncertainty in the real world may not be fully captured.
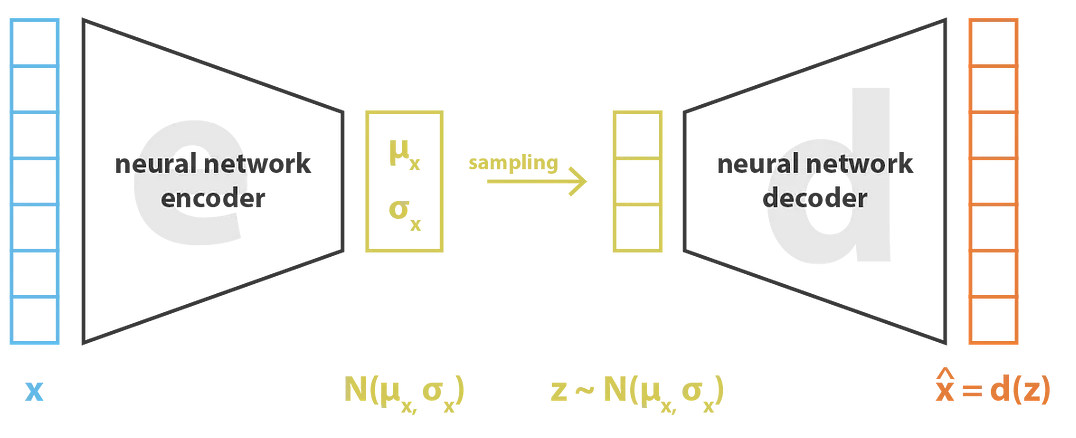
Specifically, VAEs are a method of data synthesis based on probabilistic models. It combines the ideas of self-encoder and variational inference, which can be used to generate synthetic data. By learning a potential representation space of the data, such as the probability distribution of the data learned by an encoder in Fig. 4, the VAES samples in that space to generate new composite data samples. It has the advantage of being able to generate data with diversity while maintaining continuity and consistency in the data, as they model the generation process of the data and can control the characteristics of the generated samples by adjusting parameters in underlying space.
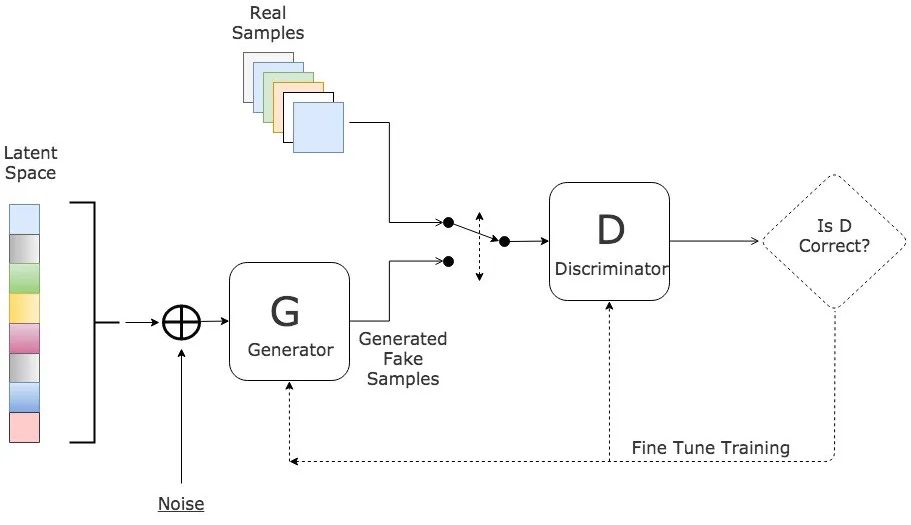
The GAN synthesizes data through two components, a generator and a discriminator. The generator is responsible for generating composite data samples, and the discriminator is responsible for distinguishing real data from composite data. As shown in Fig. 5, through adversarial training, the generator can gradually learn to generate realistic synthetic data, while the discriminator continuously improves its ability to discriminate real and synthetic data. This adversarial training process enables the GAN to generate synthetic data with a high degree of fidelity and resemblance to real data.
III. Application Scenarios of Synthetic Data
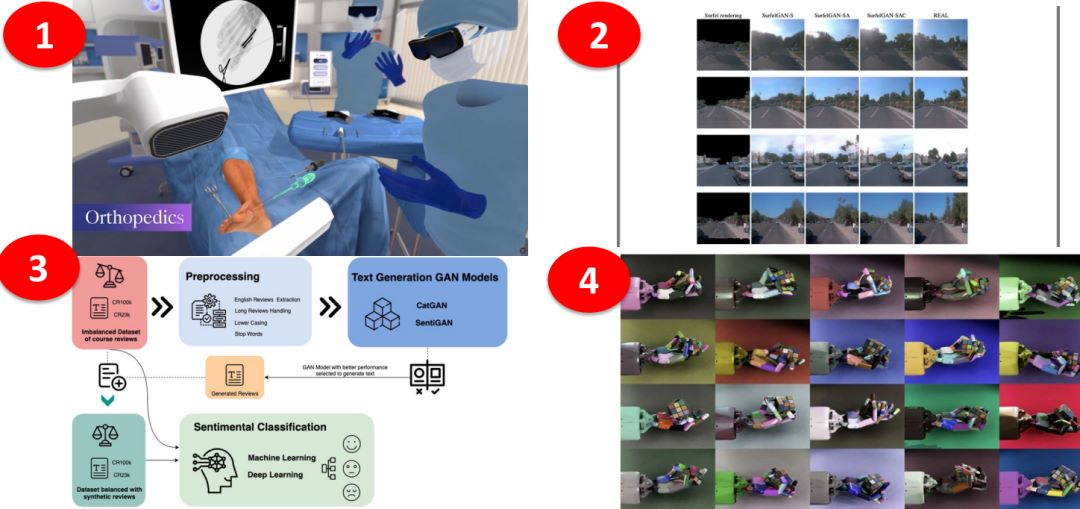
For the application scenario of synthetic data, Glenn Schmitz mentioned four examples that have achievments so far, as shown in Figure 6. First, FACS (Facial Action Coding System) published a case of applying synthetic data to orthopedic surgery. Second, DeepAI trains image segmentation and target extraction models using synthetic data. Third, OpenAI makes use of synthetic data to study semantic recognition. Finally, Ilge Akkaya published the results of training robotic arms using synthetic data.
Overall, synthetic data plays an important role in many applications. It can be used to enhance the size and diversity of real-world datasets, thereby improving the performance and generalization capabilities of machine learning models. Synthetic data can also be used to fill in missing data or address data imbalances to balance the distribution of data sets. In addition, synthetic data can also play a role in privacy protection by generating synthetic data instead of sensitive information to protect individual privacy. In the area of simulation and emulation, synthetic data can be used to create virtual environments and scenarios for testing, validation, and training, thereby reducing costs and risks. In summary, synthetic data has a wide range of application scenarios and provides valuable resources for data analysis, modeling and decision-making in various fields.
IV. The “Abyss” of Synthetic Data
Glenn Schmitz noted that while synthetic data facilitates access to training data, it still has some controversy and risk. From the ethical and moral perspective of AI, the generation process of synthetic data may be inherently “biased” due to design reasons, making the generated data have strong “personal attributes”. Moreover, from a usage point of view, when synthetic data is used for “fine tasks”, the errors it introduces can pose significant usage risks. As shown in Figure 7, when using it, you need to comprehensively consider the pros and cons, as well as weigh ethics, deviations and goals.

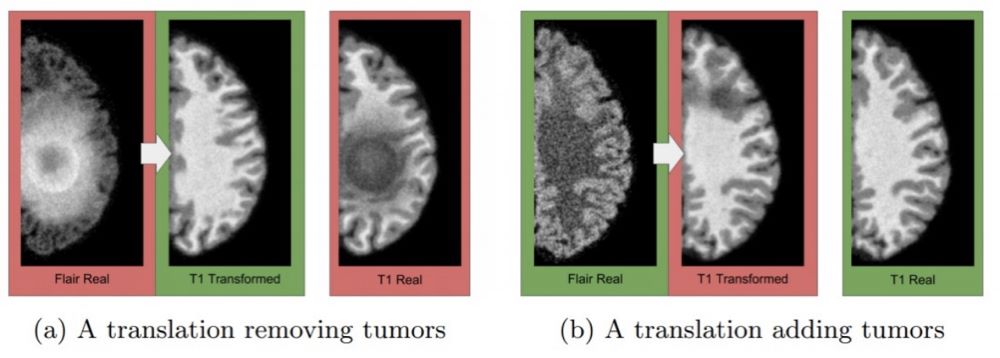
As the CycleGAN researchers point out in their paper, the output of CycleGAN is a response to “what if… What it will look like” which, while plausible, may differ significantly from the basic facts. Therefore, careful use and calibration are required in areas where critical decisions are made based on the output of CycleGAN. This is particularly important in medical applications, such as when converting MRI data to CT data. Just as CycleGAN may add bizarre clouds to the sky to make it look like Van Gogh’s painting, it may add non-existent tumors or remove real ones from medical images, as shown in Figure 8.
V. Tools for Synthesizing Data
For the convenience of researchers and developers, Glenn Schmitz enumerates some commonly used data synthesis tools as shown in Figure 9, including:
1) Mimesis: a multi-language fake data generation library that can generate various types of data, such as names, addresses and emails.
2) The Synthetic Data Vault (SDV): An open-source tool for generating synthetic data sets, which is based on statistical models and machine learning algorithms and can simulate the distribution and properties of real data.
3) Transaction data simulator: a tool used to simulate transaction data, which can generate synthetic transaction data sets for testing and analysis purposes.
4) YData Synthetic: a platform for generating synthetic data, which provides various data types and generation methods and can create synthetic data sets according to requirements.
5) Faker: A Python library for generating composite data, which can generate various types of data such as name, address and date.
In addition, there are some commonly used Python libraries, such as sklearn (Scikit-learn), faker module, PYOD (Python Outlier Detection) and CTGAN (Conditional Tabular GAN), which provide rich functions and algorithms for synthetic data generation and processing.
REFERENCES
[1] Glenn Schmitz, Angus Chen, Rise of the Machines: Achieving Data Security and Analytics with AI, RSAC, 2023
[2] Blagus R, Lusa L. SMOTE for high-dimensional class-imbalanced data[J]. BMC bioinformatics, 2013, 14: 1-16.
[3] Joseph Rocca, Understanding Variational Autoencoders (VAEs), towardsdatascience, 2019
[4] Sik-Ho Tsang, CGAN — Conditional GAN (GAN), Artificial Intelligence in Plain English, 2020
[5] Zhu, J. Y., Park, T., Isola, P., & Efros, A. A. (2017). Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE international conference on computer vision (pp. 2223-2232).